Texto universitario

_____________________________
Módulo 3. Valores P
3.1 Formar el instinto científico en los estudiantes universitarios
La palabra “ciencia” proviene del término latino scientia, que significa conocimiento o comprensión, interpretado en un sentido filosófico más amplio que en el uso moderno. La palabra “científico” no entró en uso hasta mediados del siglo XIX, cuando fue acuñada por William Whewell, un filósofo historiador, sacerdote episcopal y hombre de ciencia. Previamente los cultivadores de la ciencia se consideraban filósofos naturales[1]. Ese término tenía sentido porque destacaba la ciencia como una filosofía de cómo podemos conocer el mundo natural a través de métodos que se refieren a fenómenos naturales. La filosofía natural contrastaba con la filosofía oculta, que trataba de explicar el mundo en términos de poderes y agencias sobrenaturales. La filosofía natural no floreció realmente hasta la revolución científica del siglo XVII, pero sus raíces se remontan mucho más allá. Se pueden encontrar entre los antiguos griegos, como en la opinión de Hipócrates sobre la epilepsia, esta no debe ser vista como “enfermedad sagrada” causada por la posesión divina, sino como aflicción natural con una causa natural.
Este enfoque natural sobre los causales y los efectos, es una metodología que distingue al pensamiento científico. No es una metafísica aireada, sino una filosofía empírica completamente fundamentada. Las explicaciones científicas pueden ser “ocultas” solo en el sentido arcaico del término, que se refiere a causas que están en lo profundo de la realidad y requieren del arte del diseño experimental para sacarlas a la luz, piense en ello, cómo en años muy atrás antes del descubriendo del ADN, este no fue "verdadero" hasta la evidencia de su existencia como huella de todas las formas de vida. Parte de las maravillas de la ciencia es descubrir cómo las estructuras secretas, intrincadas y causales del mundo producen los maravillosos efectos que observamos.
Pudo haber sido Sócrates quien originalmente hablara de la filosofía como asombro. Platón le da esta línea en uno de los diálogos importantes donde discutió la epistemología, la naturaleza del conocimiento. Como es típico del diálogo socrático, los lectores se dan cuenta rápidamente de que los conceptos que habían dado por sentados no son tan sencillos después de todo. Lo que significa tener y adquirir conocimiento, que es el objeto de la epistemología, es una cuestión particularmente complicada. La propia respuesta de Platón, —nacemos con conocimiento pero necesitamos usar la razón para burlarnos de él en una forma de memoria— no parece inicialmente muy plausible para nuestra sensibilidad moderna esta frase. Estamos más en el linaje epistemológico de Aristóteles, quien argumentó que todo el conocimiento tiene su fuente de sensación. La ciencia se asienta de manera natural en este espacio empírico. Sin embargo, un Sócrates moderno volvería a señalar que las cosas no son tan simples. Tal vez no nacemos con conocimientos innatos en la forma que Platón imaginó, pero tampoco es que la mente sea una tabla en blanco. Nacemos con recursos axiomáticos para aprender sobre el mundo con una mente parcialmente preformada por la evolución. Somos capaces de reconocer la unidad de cantidad, las dimensiones espaciales, categorizamos en conjuntos las cosas, estimamos probabilidad y lo más importante, aplicamos lógica a las situaciones que se nos presentan.
En el descenso del hombre evolucionado, Charles Darwin exploró la evolución de los rasgos mentales, incluyendo la atención, la memoria, la imaginación y la razón. Demostró que incluso las características mentales humanas más avanzadas podían encontrase en formas incipientes en otros animales, y ofreció explicaciones de cómo estos instintos podrían haber sido moldeados por la selección natural[2]. Sin instintos (una combinación de lo sensorial y los recursos innatos axiomáticos) que nos preparen para el mundo, los organismo no tendrían tan buena posibilidad de sobrevivir. Un organismos que pudo, por ejemplo, descubrir relaciones causa-efecto críticas en su entorno, no tendría problemas en la dura competencia de la vida. Los seres humanos no somos diferentes. Aunque nuestro poder mental es más evolucionado también estamos obligados a descubrir la estructura causal del mundo.
Esto nos conduce a un concepto central, la verdad. Darwin es completamente típico en su respuesta, la verdad como un objetivo científico. Pero Sócrates nos advierte que seamos claros sobre lo que queremos decir con verdad. Una respuesta razonable sería decir que la ciencia tiene como objetivo el conocimiento proposicional, que implica nociones de lógica de la verdad y lo falso, aunque es posible que no sepamos cuál. Presumiblemente, el trabajo de la ciencia sería averiguarlo. Si las hipótesis científicas son solo declaraciones que expresan proposiciones, entonces tal vez la ciencia es solo para determinar su verdad o falsedad, hipótesis por hipótesis. Los positivistas lógicos hicieron un valiente intento de analizar el conocimiento, pero por razones que no nos conciernen aquí el proyecto final fracaso[3].
Algo que tiene mejor sentido para la ciencia, es la posibilidad de la verdad. Consideremos una noción más amplia de la verdad por la cual podemos referirnos a una semejanza más o menos verdadera. Una imagen es el caso más simple, y a menudo hablamos de la ciencia como la que proporciona una imagen del mundo, tal vez porque en efecto pensamos en la ciencia en términos de observaciones visuales. No hay nada de malo hablar libremente de esta manera, siempre y cuando tengamos en cuenta que podemos ser informados sobre el mundo por otros sentidos; hay limitaciones a la metáfora de la imagen, y la ciencia ciertamente no se limita a los modelos visuales. Cuando los científicos hablan de buscar la verdad, se refieren a su búsqueda con los mejores modelos del mundo. Modelar algo significa reproducirlo, producir una semejanza, en mayor o menor grado, de maneras que sean relevantes para los propios intereses.
Puede ser útil pensar en esto como la diferencia entre un binario (falso o verdadero) y lo que se puede llamar una noción analógica de la verdad. La lógica clásica tiene solo dos estados, verdadero o falso, por lo que si una proposición no es verdadera, tiene que ser falsa. Los científicos, sin embargo, saben que sus modelos nunca son perfectos, lo que en una noción binaria de la verdad implicaría que todos son falsos. Se podría argumentar que, estrictamente hablando, este es un relato preciso de nuestra situación, y solo necesitamos aprender a vivir con ella, porque solo los dioses podrían saber lo que es verdaderamente cierto. Pero tal punto de vista parece perverso y no esencialmente útil para entender la práctica de la ciencia.
Tomemos un enfoque diferente. La verdad de la lógica clásica podría considerarse como basada en un extremo de una escala de precisión o semejanza: la verdad es 100 por ciento y la falsedad siendo cero por ciento. Pero la forma de analizar las cosas de la lógica clásica confundiría algo que es casi correcto, digamos 99.9 por ciento, con algo en el extremo opuesto de la escala. En cambio, ¿qué pasa si tomamos la verdad y la falsedad como estar en los extremos superior e inferior y luego pensamos en cómo una semejanza puede ser más verdadera a medida que algo es más cierto, sino es perfectamente cierto. De manera similar, se puede hablar del grado de fidelidad: ¿qué tan buena semejanza con la realidad es el modelo M? Esto también encaja con formas comunes de hablar, como cuando preguntamos qué tan preciso es un modelo de renderizado M, o cuán fiel es una reproducción de M.
De esta manera conectamos verdad con la noción de modelado y la idea de fidelidad con la reproducibilidad, pero también debemos comprender otro aspecto clave de la metodología de la ciencia. Concretamente, se refiere a la idea de reproducibilidad en el sentido práctico de ser capaz de replicar (es decir, reproducir) los resultados. Los científicos no confían en los experimentos que no pueden replicar. Como resultado experimental, la reproducibilidad se asume como un asunto robusto, lo que significa que resiste nuevas pruebas, que razonablemente aumenta la confianza en la verdadera creencia de su modelo. Esta es una noción práctica de la verdad. A diferencia de la noción clásica, no está necesariamente ligada al lenguaje. Los modelos más verdaderos, del mismo modo, harán predicciones más precisas con mayor regularidad. Esto muestra una conexión entre la verdad y la replicabilidad.
Se podría decir mucho más sobre cómo y por qué esto tiene sentido en la ciencia, el punto importante es que cuando los científicos dicen que están buscando verdades sobre el mundo (conocimiento objetivo), están hablando de la verdad empírica que nos ayuda a hacer nuestro camino en el mundo y que necesariamente viene graduada: siempre hay valores p, intervalos de confianza, grados de probabilidad u otros indicadores de precisión asociados a todos los hallazgos científicos.
Conocimiento. Es el segundo concepto al que Darwin refiere. Filosóficamente analizamos que es el conocimiento dibujándolo cuidadosamente entre varias distinciones importantes, como la diferencia entre saber-cómo y saber-eso. Este estudio de Darwin está dentro de la epistemología. El saber-eso lo llaman conocimiento propositivo o descriptivo, es decir, conocimiento que se puede afirmar en forma de sentencias descriptivas: disertación. Esto es muy diferente de la noción más básica de saber hacer algo, que los filósofos llaman conocimiento procesal; tal vez sepa cómo lanzar una rosa, pero no ser capaz de articular ese conocimiento en ningún tipo de forma descriptiva. La relación entre saber-cómo y saber-qué es importante, pero por el momento, vamos a quedarnos con esto último y preguntar lo que significa para alguien saber de P (proposición particular). La noción clásica se remonta a Platón, quien sugirió que para que algo contara como conocimiento tenía que ser no solo una verdadera creencia, sino también una justificada, es decir, surge de un proceso de agencia racional. Una suposición afortunada, no cuenta como conocimiento. El conocimiento proviene de la razón de la evidencia apropiada, reflexionada en sus conexiones causales. La epistemología moderna ha encontrado casos en los que incluso creencias que son justificadas, todavía no pueden contar como conocimiento si el proceso por el cual se formuló la creencia del conocedor no era rigurosa.
El conocimiento científico es un tipo de conocimiento que ha sido justificado por demostraciones científicas dentro del diseño experimental generador de evidencia. Una vez más, no todas las preguntas son científicas o tienen una respuesta científica, pero las metodologías de la ciencia han demostrado ser confiables para responder preguntas empíricas sobre el mundo natural. También debemos reiterar que el conocimiento científico no es absoluto. Decir que la ciencia es un proceso confiable, no es decir que es perfecta o que después de una cierta cantidad de esfuerzo dado llega a la verdad absoluta. El conocimiento empírico de cualquier tipo es falible y la ciencia, no es una excepción.
A diferencia de la certeza formal deductiva que proporciona la matemática, la ciencia es una empresa inductiva. Esto significa que, aunque que todas las premisas del argumento sean ciertas, todavía existe la posibilidad de que la conclusión sea falsa. El conocimiento siempre viene en cierto grado de confianza. Expresando: ”los datos sugieren; parece probable; por lo que hemos visto hasta ahora” y así sucesivamente, los científicos a menudo consideran frases de este tipo no como signos de equívoco. sino de confesión de ignorancia. De hecho, lo que estos operadores lingüísticos de grado de confianza representan es la epistemología básica de la ciencia, son etiquetas lingüísticas que marcan la fuerza de la evidencia acumulada, y el reconocimiento siempre presente de que más evidencia puede sugerir un cambio. Esa es la naturaleza de la evidencia inductiva y parte de la razón por la que los descubrimientos científicos rara vez se ajustan al momento estereotipado de eureka.
Esto nos lleva al tercer elemento de la cita de Darwin: el descubrimiento. Cada científico sueña realizar un nuevo paso en la frontera de lo desconocido… el oficio de revelación del funcionamiento natural revela hechos y elabora métodos útiles. Uno puede descubrir no solo X, sino también cómo afecta Y. En cualquier caso, el núcleo de la noción de descubrimiento está en la semántica de la misma palabra; revelar y hacer relaciones lógicas y traer luz a lo que antes estaba en las sombras. Los descubrimientos suelen darse lentamente con un acumulado de conocimiento que revela algo del mundo y sus posibilidades. Pero un descubrimiento requiere disertación (comprensión) no solo sobre el qué, sino la razón del por qué.
Razonamiento. Filosoficamente, sabemos que la razón exige que este estándar de descubrimiento más alto se cumpla antes de que uno explore algo como un verdadero descubrimiento científico. Para poner las bases, devolvamos nuestra atención a nivel precientífico e instintivo que Darwin postuló.
Darwin señaló que los rasgos mentales evolucionaron. Las formas rudimentarias o precursores de los rasgos humanos se encuentran en otros animales. Dado este descubrimiento, debemos esperar igualmente que el conocimiento científico surgiera de formas de conocimiento más simples que precedieron a las científicas e incluso a la evolución mental de los seres humanos. En este nivel básico, el descubrimiento tiene raíces en el lenguaje desde un punto de vista evolutivo, saber-cómo precede a saber-qué. El primer reto para un organismo es cómo sobrevivir. ¿Cuánto necesita saber para ello? Solo tiene que ser suficientemente bueno en la práctica. ¿Qué también debe razonar? Lo suficiente. A medida que los rasgos mentales axiomáticos innatos (conteo, propiedades del espacio, categorizar, probabilidad y lógica) se vuelven más complejos, los conceptos de conocimiento y razón también se vuelven más estructurados extendiendo la lógica y las herramientas del lenguaje natural. El instinto científico de la razón tiende a manifestarse desde estos axiomas innatos como un impulso a explorar y averiguar realizándonos preguntas y creando conceptos, teorías y planteando problemas. Esto puede experimentarse inicialmente como una vaga sensación de necesidad de saber, una incomodidad de ignorancia, similar a un susurro de la mente hasta una pregunta que desconcierta, sentimos una confusión básica con nuestras creencias más elementales de nuestros axiomas. Para organismos con rasgos mentales superiores lingüísticos como nosotros, las formas de estructurar conceptos, hechos, teorías, evidencia, problemas, preguntas, métodos, técnicas… nuestra racionalidad está limitada, pero en colaboración con sociedades de investigadores, el poder cognitivo se amplifica mejorando nuestros rasgos de estilo de pensamiento. El punto es que los axiomas de nuestra cognición alimentan nuestra curiosidad, es decir la agencian de justificaciones. En resumen la curiosidad es un instinto que Darwin expresó necesario para sobrevivir en el mundo.
La curiosidad es un instinto, y los instintos son respuestas “definidas y uniformes” a sensaciones o asociaciones particulares. Estos instintos impulsan los comportamientos y al menos en su forma más básica no se requieren aprender de la experiencia. Por su puesto, decir que los instintos no requieren aprenderse de la experiencia, no significa que estos no puedan mejorar y ser la diferencia de nuestra actitud a partir del aprendizaje posterior a los instintos básicos. Incluso los cantos característicos de las aves se modifican en versiones variantes dependiendo de los dialectos que las aves infantiles escuchen a su alrededor.
Presumiblemente, los complejos entornos y las complejas relaciones con las que los seres humanos tienen que lidiar hicieron que la flexibilidad de la alta inteligencia y el aprendizaje sea más valiosa para nosotros a largo plazo, pero el punto de Darwin es que todos los rasgos mentales tienen que ser adquiridos en grados. Nuestro poder intelectual superior debe haber evolucionado sobre una base de instintos más simples. Sería un error para nosotros pensar que nuestra inteligencia nos ha alejado del reino del instinto animal.
Darwin observó los instintos, particularmente en la forma en que se exhiben incluso en los bebés antes de cualquier experiencia. Nadie que haya interactuado con animales jóvenes —mascotas o incluso sus hijos— duda de la evidencia de su interés innato en explorar las novedades en su entorno. La curiosidad se extiende a nuevos estímulos a través de modos sensoriales y también el interés por el mundo. Algunas personas viven la ansiedad de buscar nuevas cosas, mientras otras se adhieren a la cotidiano si pueden, graduando la realidad en capas de abstracción. El instinto de la curiosidad también está sujeto a la selección natural, si la curiosidad siempre o incluso por lo general matará al gato; la evolución habría terminado rápidamente con esta disposición. Pero eso no es lo que observamos y no es difícil ver cómo la curiosidad proporciona una ventaja evolutiva selectiva en muchos entornos.
La curiosidad es un rasgo epistémico ventajoso para un organismo que con su juego de sensores y axiomas, es útil para adquirir conocimiento. La curiosidad y otros rasgos instintivos nos permiten averiguar nuestro único mundo parcialmente predecible. Si el mundo fuera completamente regular en todas las formas que importan a los organismos, no tendrían que ser curiosos. En un mundo con recursos limitados e irregularmente ubicados en el espacio tiempo, su posibilidad de sobrevivir y reproducirse sería una cuestión de desviarse de caminos trillados y ensayar algo nuevo.
En estos mundos, una disposición a investigar las novedades y a salir del camino estándar para probar nuevos conocimientos puede tener una utilidad real, dando a los organismos una ventaja competitiva. Sin tal instinto, el descubrimiento de nuevos recursos sería menos probable. Incluso los mecanismos elementales de investigación podrían proporcionar una ventaja. Freud tenía razón en que también es útil para el sexo. Incluso los organismos bien dotados no irán bien en la competencia evolutiva si no pueden encontrar pareja o cualquier otra cosa necesaria para reproducirse.
Además, al considerar el valor de la búsqueda de novedades, es importante tener en cuenta que, si bien lo nuevo puede ser útil, también puede ser peligroso. Ese susurro de curiosidad es posible que esté detrás un depredador. La capacidad de identificar nuevos peligros y aprender a evitarlos también es de valor adaptativo. Tenemos que admitir que la curiosidad a veces mata al gato. Los organismos que siempre se precipitan rápidamente donde otros temían pisar, a veces entran en peligro. Un poco de precaución está en el orden, lo que tal vez explica por qué la curiosidad se experimenta inicialmente como una especie de inquietud… la sensación de que algo no está del todo bien o de que no es.
Hay dos posibles repuestas a las anomalías percibidas. La respuesta conservadora es ignorar las diferencias y seguir con las generalizaciones establecidas. La respuesta progresista y curiosa es investigar las diferencias con esperanza de descubrir una generación los modelos más amplia y precisa. Este último enfoque tiene la ventaja adaptativa de la autocorrección y el descubrimiento de patrones nuevos o más amplios. Cada una de estas posiciones está confundida, una respuesta intratable podría ser inicialmente más segura, pero una respuesta curiosa proporciona una oportunidad para el aprendizaje. El primer trabajo de un organismo es descubrir las regularidades e irregularidades de su mundo, y esto es ciertamente cierto para los seres humanos. Freud pensó que la curiosidad humana siempre era en última instancia sexual, pero aunque, por supuesto, reconocemos la importancia de la reproducción en un relato evolutivo, hay una ventaja más general que es un requisito previo incluso para esta. Los bebés lo hacen, debemos ser capaces de averiguar la estructura causal del mundo, y esto requiere atender patrones ocultos y notar violaciones a modelos existentes. Esto es lo que hacen los bebés, necesitan ser capaces de hacer cognición inductiva, que es la capacidad de aprender y generalizar a partir de nuevas experiencias. Los datos novedosos alteran las regularidades familiares, a veces el diseño de nuevos experimentos, revelan regularidades más profundas. La previsibilidad es útil, y por tanto una vez que algo ha sido comprobado y es familiar, entonces las cosas se vuelven predecibles de nuevo. La previsibilidad es útil y por lo general se necesita curiosidad para descubrirla.
3.1.1 De la confusión a la satisfacción
Cuando un organismo se aparta de un camino regular, ¿cómo podemos saber que está impulsado por la curiosidad en lugar de la confusión? A primera vista, uno parece positivo, activo y adaptativo mientras que el otro parece negativo, pasivo y no adaptativo. Los dos están estrechamente relacionados en que ambos implican una respuesta a una desviación de un patrón esperado. Ambas son reacciones a algo en el entorno que difiere del mapa conceptual (o de algún conflicto dentro del mapa conceptual) e indican una discordancia con las expectativas. Ambos implican una sensación de desconcierto. Estamos desconcertados cuando descubrimos una anomalía en lo que habíamos visto anteriormente como una regularidad. Es como si el flujo de percepción va ¿qué?, ¿porqué? La desviación de la expectativa es confusa. Las anomalías de cualquier tipo se perciben como desconcertantes y también como potencialmente interesantes.
Prestamos atención a los patrones de similitud y diferencias en nuestro entorno. La aleatoriedad pura no es interesante; si tocamos ruido blanco, después de unos minutos ya ni siquiera lo vemos. La repetición simple también puede ser aburrida. Estamos programados por la evolución para notar las regularidades y las irregularidades y para tratar de averiguar cómo resolver cualquier anomalía. Este interés se mezcla con la emoción, tal vez relacionada con la sensación producida cuando el cuerpo se prepara para un posible peligro, o de otra manera anticipar la acción.
Además, la curiosidad, como todos los demás rasgos, es variable entre los individuos. Algunos responden solo a la novedad extrema, mientras otros sienten picazón de la curiosidad con más intensidad. Al final, el sentimiento emocional que proviene de la resolución de la tensión inquisitiva es un tipo especial de placer y para las personas que son profundamente curiosas, el sentimiento puede ser profundo. Como cualquier gato que muera de curiosidad lo atestiguaría, la resolución de algún tipo rompecabezas es un sentimiento de máxima satisfacción.
En el sentido moral de Darwin. Hasta ahora, nos hemos centrado en la extraña sugerencia de Darwin de que tenemos un instinto de verdad, conocimiento de descubrimiento, y hemos argumentado que es razonable pensar en la curiosidad como un instinto evolucionado. Pero ahora queremos pasar a la sugerencia aún más asombrosa que hizo, a saber, “algo de la misma naturaleza que el instinto de la virtud”. ¿Qué podría significar decir que la curiosidad es virtud? ¿Y por qué hablar de la virtud misma como instinto?
La universidad forma científicos, los dota del poder intelectual de pensar, disertar, diseñar experimentos, procesar evidencia, comunicar su literatura, discutir la verdad y hacer felices a estos exploradores aprendices en el difícil camino del lenguaje de los hechos y las inferencias matemáticas de su elegante literatura.
Para ayudar a contar la historia del oficio del científico, veamos primero los propios puntos de vista de Darwin sobre la evolución de lo que él llamó el sentido moral. La moralidad, hipotéticamente, se hizo posible cuando en los animales que habían evolucionado los instintos sociales alcanzaron un grado suficiente de poder intelectual. Por instintos sociales, Darwin tenía en mente aquellos sentimientos que llevan a los animales a disfrutar de la simpatía, como los afectos de los padres. Explicó cómo tales comportamientos de ayuda instintiva podrían proporcionar a los animales una ventaja competitiva en diversas circunstancias, mejorando las posibilidades de supervivencia en un grupo de individuos relacionados. Tales comportamientos podrían ser esencialmente para el cuidado parental de los jóvenes o incluso el aseo mutuo que elimina útilmente los parásitos. A corto plazo, tales instintos podrían ser particularmente poderosos, pero en combinación con la memoria y la imaginación mejoradas, pueden convertirse en sentimientos más fuertes de insatisfacción asociados con instintos incumplidos. Estos sentimientos, sugirió, son la voz incipiente de la conciencia. Ser capaz, con mayor inteligencia, de recordar tales sentimientos del pasado e imaginar el mismo efecto en el futuro, si se descuidaron las conductas de ayuda, proporciona una indicación de lo que deben o no deben hacer —que es el sentido moral—. Darwin no pensaba que pudiéramos atribuir adecuadamente la moralidad a los animales de la misma manera que lo hacemos a los seres humanos, pero hipotetizó que cualquier animal con la capacidad instintiva de empatía, junto con un grado suficiente de inteligencia, llegaría a sentir un imperativo moral para comportarse en consecuencia.
Es necesario tener precaución; el hecho de que necesitamos ciencia evolutiva para ayudar a explicar nuestra capacidad moral no implica que podamos leer reglas éticas directamente de la biología. La supervivencia del más apto es un poderoso principio explicativo para entender el mundo biológico, pero la teoría ética hace que este principio tenga una fractura. Consideren este experimento mental que Darwin propuso: “si los seres humanos fueran criados exactamente en las mismas condiciones que las abejas de colmena, entonces las hembras solteras, como abejas trabajadoras, pensarían que es su deber sagrado matar a sus hermanos y las madres se esforzarían por matar a sus hijas fértiles; y a nadie se le ocurriría interferir[4]”. Si un sentido moral evolutivo funcionara de esta manera, el problema sería obvio: cometer una variación de la falacia que el filósofo escocés del siglo XVIII David Home identificó al tratar de derivar un “debe” moral de un mero “es”. La falacia es obvia una vez que se señala: que algo es el caso no implica por sí mismo que debe ser así. Se necesitará un razonamiento un poco más filosófico para encontrar alguna premisa moral que vincule las afirmaciones fácticas con las conclusiones morales. Darwin mismo dio algunos pasos tentativos con la teoría ética kantiana y utilitaria.
Este breve panorama, es suficiente para ver cómo Darwin pensó en la evolución del instinto de la virtud y algunas de las complejidades que tendrían que ser resueltas a medida que avanzamos. Algunos teóricos no piensan que la falacia naturalista es una falacia en lo absoluto. Alistair McIntyre, pensó que las declaraciones sobre lo que es bueno, son solo una especie de declaraciones fácticas[5]. Dejando a un lado esta cuestión, como con el sentido moral, no se debe esperar derivar una sólida noción ética de la normatividad de las consideraciones biológicas por sí sola. Sin embargo, el relato evolutivo del origen de la curiosidad como instinto puede recibir importancia normativa cuando se pone en un contexto filosófico. Tanto Darwin como Home lo habrían encontrado atractivo. Los rasgos de carácter, como la curiosidad son esenciales para hacer ciencia.
Como punto preliminar, no hace falta decir que la virtud no se limita a la moral sexual, que es quizás lo que primero viene a la mente para aquellos que piensan en la mojigata noción victoriana de proteger la virtud de uno. Tampoco debemos pensar en la virtud como pasiva, que es una connotación que el término a veces lleva hoy. La virtud no es una estado de reposo del ser. Quiero recordar un elemento más tradicional del concepto de virtud, a saber, la virtud como poder. Conservamos un remanente de este significado en una frase de como “en virtud de lo cual” que, como “sobre la fuerza de”, transmite la idea de una propiedad, poder o capacidad de disposición que haga algo posible o haga que así sea. Moliére tenía esta noción activa de la virtud como un poder cuando se burlaba de las explicaciones triviales: ¿Por qué el opio hace que uno duerma? Porque tiene una “virtud dormida[6]”. Se puede decir razonablemente, por ejemplo, que un material o molécula es fuerte o frágil en virtud de su estructura física o química. Debemos pensar en las virtudes de carácter que son nuestro tema de una manera similar, son rasgos intelectuales que nos disponen a comportarnos de manera confiable y de maneras apropiadas. Están orientadas a la acción, dándonos el poder y la motivación para actuar como lo justifica la situación. En el ámbito mental, la virtud tiene la connotación de referirse no a ningún poder o disposición, sino principalmente a cualidades creativas. De hecho, muchos clásicos aristotélicos traducen “virtud” como excelencia o una vida en el arte.
Aristóteles, consideró que excelencia o virtud es “una disposición asentada en la mente que determina nuestra elección y emoción” que consiste esencialmente en observar un equilibro relativo a nosotros… una medida entre dos vicios, lo que depende de los excesos y lo que depende del defecto. Encontrar equilibrio adecuado, rara vez es una cuestión sencilla de seguir por una regla, por lo general debe ser determinado por un principio racional y el ejercicio del juicio, razón por la cual hablamos de la idea de preguntar cómo una persona con “sabiduría práctica” juzgaría dónde cae el equilibrio en situaciones dadas.
Esta es una noción general razonable, pero los detalles específicos del relato de Darwin serán de menos uso directo, por la razón obvia de que tenía como objetivo entender la virtud para nosotros como seres humanos, mientras que estamos interesados principalmente para los científicos en su práctica vocacional. Un relato más estrecho y más especializado. Para estos contextos, deseamos introducir la idea de la virtud vocacional como una disposición del oficio de explorador, tejedor de argumentos en su literatura y mentor de nuevas generaciones.
Aunque Darwin ilustró que la curiosidad es un instinto y una virtud científica, es algo con lo que no nacemos, debe ser cultivada. Aristóteles tenía razón en que esto se hace por actitud diaria, uno debe practicar su modo de pensar al leer y escribir, además de someter el diseño experimental a criterio de causalidad y probabilidad en el contexto de datos y evidencia. Esta curiosidad científica tiene una base en el instinto, pero es necesario educarla para aprender a caminar en el espacio de incertidumbre. La curiosidad científica es más exigente que el tipo ordinario con el que todos nacemos. Implicará métodos distintos, criterio sobre lo verdadero y lo que existe, habilidades especializadas de lenguaje matemático.
Aprender a hacerlo bien, esta vocación científica toma años de entrenamiento y son las universidades donde estos aprendices responden a preguntas de su vocación. Debido a que son desafiados con aspectos causales y evolutivos, la virtud puede considerarse un concepto de un artista del pensamiento de disertación y el diseño experimental. Home consideró a esta virtud la posesión de cualidades mentales (intelectuales), útiles o agradables para la persona misma y, lenguaje para hacer consensos sobre los sistemas de argumentos y discusiones. Home no tenía una explicación de cómo esos sentimientos internos podrían llegar a ser, pero la explicación de Darwin de cómo evolucionan los instintos muestra cómo rasgo de carácter la curiosidad instintiva implicada en valores epistémicos de verificación, simplicidad, experimentación, racionalidad, originalidad…, requiere procesamiento intelectual para crecer en el espacio de razones, justificaciones, inferencias, evidencias, teorías comenzando con una explicación de los métodos de la ciencia.
¿Cuál es el propósito central y orientador de la ciencia?, tiene como objetivo describir verdades sobre el mundo natural, teniendo como herramienta la conciencia, el lenguaje natural (español, inglés, italiano) y el artificial (computacional y matemático). Los científicos buscan la verdad entre sus grados de certeza empírica. Los científicos desean medir una constante a un nuevo grado de precisión, aislar un nuevo compuesto, descubrir una nueva especie o descubrir una nueva ley física, química, biológica. Y estas son las cosas que hacen felices a los científicos hasta el núcleo de lo que es su identidad. Educar a un joven universitario en la ciencia, es desarrollar la excelencia del hábito de escribir y leer disertación, hacerlos capaces del arte de diseño experimental y el procesamiento de datos satisfaciendo la curiosidad por la verdad hipotética inductiva de lo que existe. Las existencias siendo un mundo de capas subyacentes de significado de la realidad, observador y objeto de la realidad, crean comunidades de pensamiento que discuten, justifican y deliberan sobre lo real.
La virtud de la curiosidad científica, es el cultivo de valores epistémicos, ontológicos y metodológicos de lo más riguroso y elegante en este estilo de pensamiento de disertación. Y estos valores le dan el significado cotidiano de su integridad moral cuando: fundamenta, justifica, explica, demuestra, calcula, describe, categoriza y narra los hechos y evidencias en un cuerpo teórico. La comunicación de los científicos es fundamentalmente por su literatura clara, coherente, rigurosa, elegante y objetiva.
3.2 Un científico universitario en expansión
Un cambio en nuestras creencias más fundamentales las destina a enfrentar la resistencia. No somos ajenos a esto; nos hemos encontrado con la oposición a nuevas formas de pensar toda nuestra vida. Cuando éramos niños, por las noches meditábamos en descubrir en un telescopio o microscopio una vida como científicos, mirando las maravillas a través de la razón. Pero la realidad parecía recordarnos que esto era solo un sueño. Al ingresar al primer grado, los estudiantes teníamos referentes de nuestros padres campesinos, carpinteros, soldadores, panaderos…, Justo allí surgió la pregunta de ¿por qué el cielo es azul?. La respuesta del profesor fue, lo “dicen los libros”, y entonces la siguiente pregunta fue: ¿Quiénes hacen los libros? Fue hasta la era de mis estudios de ingeniería que un profesor expresó que el arte de pensar es la fuente de los libros y de las explicaciones incluyendo teorías sobre el color con que percibimos al cielo azul.
Seguimos encontrando intolerancia a las nuevas ideas. Los científicos están capacitados para hacer innovadoras preguntas, pero también están entrenados para ser cautelosos y racionales; su interrogatorio generalmente está dirigido a ganar profundidad incremental, no al derribo de paradigmas (modelos dominantes de explicación). Ser científico es recoger frutas y bayas evadiendo depredadores y permaneciendo vivos el tiempo suficiente para procrear ideas y diseñar experimentos para comprender la naturaleza matemática de la existencia.
“Una cosa que he aprendió en una larga vida”, dijo Einstein, “es que nuestra ciencia, medida contra la realidad, es primitiva e infantil, y sin embargo es la cosa más preciada que tenemos”. Las ciencias deben trabajar con conceptos operativos simples que la mente humana pueda comprender al trasformarlos en datos. Pero a medida que la evidencia del poder de nuestra conciencia crece con el poder lingüístico humano, la ciencia puede ser la clave para responder a preguntas que antes pensaba estaban más allá de sus fronteras, las que nos han plagado desde antes del comienzo de la civilización.
Este será el comienzo de un manuscrito, pero no es el comienzo de nuestra historia. Eso es porque nos estamos hundiendo en una odisea en curso dentro de la literatura de los héroes del pensamiento. Es una vida que ha comenzado a leer a los gigantes del pensamiento dentro de sus conexiones de justificación y fundamentos. Nos estamos asentando mucho después de que los créditos académicos de apertura tuvieran sentido. Es igual al Renacimiento, ese que fue testigo de una transformación en la forma que los humanos intentaron entender el cosmos. Pero incluso cuando la superstición y el miedo perdieron lentamente su control sobre nuestra curiosidad, la visión establecida que surgió distaba una división firme entre dos entidades básicas: los observadores pegados a la superficie de nuestro pequeño planeta, y el vasto reino de la naturaleza que constituye un cosmos casi totalmente separado de nosotros mismos. La suposición de que estas entidades —conciencia y realidad— son dos bolas de cera completamente diferentes ha impregnado tanto el pensamiento científico que es probable que todavía sea asumido por el lector incluso ahora en el siglo XXI.
Sin embargo, la opinión opuesta no es nueva. Los primeros maestros sánscritos y taoístas declararon unánimemente que cuando se trata del cosmos, “todo es Uno”, es decir, materia y conciencia. Una unidad entre el observador y el llamado universo externo o extralingüístico, a medida que transcurrieron los siglos, eran consistentes en mantener que tal distinción es ilusoria. Algunos filósofos occidentales como Berkeley y Spinoza desafiaron los puntos de vista prevalecientes sobre la existencia de un mundo externo y su separación de la conciencia. Ahora mismo el modelado matemático estadístico considera el sesgo cognitivo como una fuente importante de error inseparable del observador y su modelo predictivo. Sin embargo, el paradigma dicotómico entre mente y materia siguió siendo el consenso de moda, especialmente en el mundo de la ciencia positivista.
Pero la minoría consiguió un megáfono importante hace un siglo, cuando algunos de los creadores de la teoría cuántica, sobre todo Erwin Schrödinger y Niels Bohr, concluyeran que la conciencia es fundamental para cualquier verdadera comprensión de la realidad. Si bien la escritura creativa de disertación es el medio para la conciencia, fueron las matemáticas el experimento de laboratorio mental, en el curso de la formación de ecuaciones que formarían la base de la mecánica cuántica y sus innumerables éxitos, por lo tanto, también fueron pioneros que ayudaron a poner en la mesa el papel lingüístico de la conciencia, un siglo más tarde en apoyo con el terreno computacional de la racionalidad humana asistida por ordenador.
Hoy en día las rarezas del mundo cuántico han llevado a la minoría cada vez más a la corriente principal del pensamiento moderno. Si es realmente cierto que la vida y la conciencia disfrutan de una clarificación inmediata. No son solo resultado de laboratorios extraños como el famoso “experimento de la doble hendidura” que no tiene sentido a menos que la presencia del observador esté íntimamente entrelazada con los resultados. A nivel cotidiano, cientos de constantes físicas como la fuerza electromagnética llamada “alfa” que gobierna los enlaces eléctricos entre los átomos (enlaces químicos) son idénticos en todo el universo y “establecidos en piedra” precisamente en los valores que permiten la existencia de vida. Esto podría ser simplemente una coincidencia asombrosa. Pero la explicación más simple es que las leyes y condiciones del universo permiten al observador porque el observador las genera con su base axiomática.
Nos sumergiremos en lo que Niels Bohr, el gran físico Nobel, quiso decir cuando dijo: “no estamos enseñando a los estudiantes universitarios a medir el mundo; lo estamos creando”. Enseñar a pensar es desenredar la lógica que la mente científica utiliza para generar nuestra experiencia espaciotemporal y obtener información sobre problemas de como surgen a la conciencia, explorando aquellas regiones de la realidad enredadas en el cerebro que juntas constituyen el sistema de asociación con la sensación unitaria del “yo” observador.
En la medida que reconocemos cada vez la vida más como una aventura que trasciende nuestra comprensión de sentido común, también obtendremos pistas sobre los experimentos del pensamiento, que se pueden utilizar para explicar por qué estamos aquí ahora a pesar de las probabilidades abrumadoras en nuestra contra.
Todos nosotros somos prisioneros de nuestros primeros adoctrinamientos en el hogar, porque es difícil, muy casi imposible, sacudirse el primer entrenamiento de uno. Por eso estos son tiempos peligrosos para la ciencia, cuando sus conocimientos contradicen a los políticos o empresarios.
Es emocionante porque algunas de nuestras preguntas más profundas por fin están siendo respondidas y nuestros problemas humanos están en la cúspide de ser resueltos. Los cambios científicos son más obvios cuando comparamos el mundo de hoy con el que algunos de nosotros estudiantes de ciencias hace solo unas dos décadas atrás. Este programa universitario pretende empujar aún más los límites de la educación del estilo de pensamiento científico.
Este programa no es para aquellos que se resisten a creer en la evidencia que tienen ante sí. En cambio, está dirigido a estudiantes que son receptivos a revelaciones importantes basadas en observaciones y experimentación, porque eso es lo que es la conciencia, incluso si nuestro enfoque final es contraintuitivo.
Dado que el conocimiento es sine qua non de la ciencia, y la percepción sensorial y cognitiva basada en axiomas, son la única manera de adquirir conocimiento, la conciencia debe parecer más básica para nuestra comprensión que cualquier metodología neuronal o subsistema. Después de todo, si la conciencia humana contiene sesgos o peculiaridades fundamentales, esta podría colorear todo lo que vemos o aprendemos. Así que nos gustaría saber esto antes de continuar en nuestros innumerables métodos de adquisición de información científica, ya sean clasificaciones de datos y regresiones o taxonomías de formas de vida. La conciencia es la raíz. Es más fundamental que el disco duro de su computadora. En esta analogía, es más bien como la corriente eléctrica. Además, los experimentos desde la década de 1920 han revelado inequívocamente que la mera presencia del observador cambia una observación. Trata entonces y ahora como una rareza o inconveniente, este fenómeno sugiere fuertemente que no estamos separados de cosas que vemos, escuchamos y contemplamos. Más bien, nosotros —la naturaleza y el observatorio— somos una especie de entidad inseparable. Esta simple conclusión se encuentra en el corazón de la conciencia.
Pero, ¿qué es esta entidad? Desafortunadamente, dado que la conciencia se ha estudiado superficialmente y en gran medida sigue siendo un misterio, la amalgama que es “conciencia y materia” es igualmente enigmática, de hecho, más aún. Al estudio superficial, referimos que mientras que la neurociencia ha progresado impresionantemente desde la determinación de qué partes del cerebro controlan varias funciones sensoriales y motoras hasta explorar cómo las redes complicadas de neuronas codifica conceptos, este mismo campo ha hecho poco para revelar problemas fundamentales profundos sobre cómo la conciencia surge de la materia en primer lugar, el llamado “gran problema de la conciencia”.
Tal vez la investigación no quiere, ya que esos problemas fundamentales han demostrado ser obstinados e inmunes a la elucidación a través de las herramientas habituales de la ciencia. ¿Cómo empezar a diseñar un experimento que resulte en información objetiva sobre este fenómeno subjetivo?
No se puede negar que los científicos tienen los mismos sueños y prejuicios que todos los demás, y tienen puntos de vista que pueden no ser siempre del todo objetivos. Lo que un grupo de científicos llama “consenso”, otros lo ven como “dogma”. Lo que una generación considera un hecho establecido, la próxima generación demuestra ser un malentendido ingenuo. Al igual que en la religión, la política o la educación, los argumentos siempre han estallado en la ciencia. A menudo existe el peligro de que, mientras una cuestión científica sigue sin resolverse, o menos abierta a dudas razonables, las posiciones que ocupan cada lado del argumento pueden convertirse en ideologías arraigadas. Cada punto de vista puede ser matizado y complejo, y sus defensores pueden ser tan inquebrantables como serían en cualquier otro debate ideológico. Y al igual que con las actitudes sociales sobre religión, política o cultura a veces necesitamos una nueva generación para venir, sacudirnos los grilletes del pasado y hacer avanzar el progreso del debate.
Pero también hay una distinción crucial a la ciencia, en comparación con otras disciplinas. Una sola observación cuidadosa o resultado experimental puede hacer que una visión científica o una teoría de larga data sean obsoletas y reemplazables con una nueva visión del mundo. Esto significa que esas teorías y explicaciones de los fenómenos naturales que ha sobrevivido a la prueba del tiempo son las que más confiamos. La tierra va alrededor del sol y no al revés; el universo está en expansión y no estático; la velocidad de la luz en un vacío siempre mide lo mismo sin importar la velocidad con la que se mueva el observador; y así sucesivamente.
Ante una nueva idea que se hace de un descubrimiento científico importante, que cambia la forma en que vemos el mundo, no todos los científicos la comprarán en él inmediato tiempo, pero ese es su problema; el progreso científico es inexorable, que, por cierto, siempre es algo bueno: el conocimiento y la iluminación son siempre mejores que la ignorancia. Comenzamos con no saber, pero buscamos averiguar… y aunque podamos discutir en el camino, no podemos ignorar lo que encontramos. Cuando se trata de nuestra comprensión científica de cómo es el mundo, la noción de que la ignorancia es dicha carga tiene sentido. Como dijo Douglas Adams una vez: “yo tomaría el asombro de la compresión sobre el asombro de la ignorancia cualquier día[7]”.
3.3 Causalidad
Dibujar inferencias causales sólidas a partir de datos de observaciones, es un objetivo central en las ciencias. Cómo hacerlo, es controvertido como todo arte. Los enfoques técnicos basados en modelos estadísticos (modelos gráficos, modelos de ecuaciones estructurales no paramétricas, estimadores de variables instrumentales, modelos bayesianos) están proliferando en las nuevas tecnologías de análisis como la Inteligencia Artificial (IA). Los defensores del modelado estadístico a veces afirman que sus métodos pueden salvar un diseño de investigación deficiente o de datos de baja calidad. Algunos sugieren que sus algoritmos son motores de inferencia de propósito general. Las suposiciones de modelado se hacen principalmente por conveniencia matemática, no para la verosimilitud. Las suposiciones pueden ser verdaderas o falsas, normalmente falsas. Cuando las suposiciones son verdaderas, se mantienen los teoremas sobre los métodos. Cuando las suposiciones son falsas, los teoremas no aplican. Desarrollemos este línea de pensamiento un poco más. En particular, el problema de descripción al conjunto de solución de las ecuaciones de condiciones de optimización nos exigen una introducción sobre nuestra idea de causal[8].
Las inferencias causales se pueden extraer a partir de datos no experimentales. Sin embargo, no se pueden establecer reglas mecánicas para la actividad. Desde Home, eso es casi truismo. En cambio, la inferencia causal parece requerir una enorme inversión habilidad, inteligencia y duro esfuerzo. Se deben desarrollar muchas líneas convergentes de evidencia. La variación natural debe ser identificada y explorada. Los datos deben ser recogidos. Hay que considerar a los sesgos. Las explicaciones alternativas deben ser exhaustivamente probadas. Antes que nada, la pregunta correcta debe ser enmarcada en la teoría disponible.
Naturalmente también hay problemas a superar, existe el deseo de sustituir el capital intelectual por el trabajo de aplicación instrumental para aumentar las publicaciones científicas. Es por eso que algunos investigadores tratan de basar la inferencia causal en exclusivamente modelos estadísticos. Las tecnologías son relativamente fáciles de usar, prometen abrir amplia variedad de preguntas al esfuerzo de investigación. Sin embargo, la desaparición del rigor metodológico puede engañarnos. Los propios modelos exigen un escrutinio crítico ontológico y del mejor pensamiento estadístico. Se utilizan ecuaciones matemáticas para ajustarse a los sesgos y otras fuentes de error. Estas ecuaciones pueden parecer demasiado precisas, pero normalmente derivan de muchas opciones algo arbitrarias. ¿Qué variables introducir en la regresión? ¿Qué forma funcional usar? ¿Qué suposiciones hacer sobre los parámetros y los términos de error? Estas opciones rara vez son dictadas por los datos o conocimientos estadísticos previos. Es por ello que el juicio del pensamiento estadístico es tan importante, la oportunidad de error es grande y el número de aplicaciones exitosas tan limitadas.
La inferencia causal en experimentos controlados aleatorios que utilizan el principio de tratamiento crítico, siempre la inferencia se basa en el modelo de probabilidad subyacente real implícito en la aleatorización. Pero algunos científicos ignoran el diseño y en su lugar usan la regresión para analizar datos de experimentos aleatorios. El tratamiento crítico es un proceso de disertación riguroso, revisión de experimentos que requieren un trabajo de rigor y conocimiento transversal a los estudios reportados. Incluso un científico sin un experimento real o natural, con esta experiencia de disertación puede ser capaz de combinar estudios de casos y otros datos de observaciones para descartar posibles conexiones y hacer inferencias casuales.
Los investigadores que se basan en datos observacionales necesitan evidencias cualitativas y cuantitativas para ser conscientes de los principios estadísticos y alertar sobre posibles sesgos que pudieran sugerir preguntas más agudas de investigación.
Las matemáticas pueden ser elegantes, pero la idea básica es que las leyes de la naturaleza son solo resúmenes o sistematizaciones de las regularidades que ocurren en el mundo[9]. El problema aquí es que nuestra experiencia de regularidad solo puede ser de lo que es regular hasta ahora en nuestra conciencia. En casos que hemos observado, A han sido seguidos por B, pero dado que nada sobre A hace que B ocurra, entonces no da justificación racional para decir que en el futuro A será seguido por B. Sin embargo hay una debilidad adicional de una visión constante de conjunción de variables oponentes. Podría decirse que la teoría no tiene recursos para distinguir entre causas y coincidencias. ¿No debería haber realmente una distinción entre las regularidades que son realmente causales y las que son meramente accidentales?
¿Tendemos a distinguir las coincidencias de los casos causales? Ganar una apuesta en carreras de caballos cuando uno usa la camisa roja, podría ser una coincidencia. ¿Qué pasaría si lo mismo sucede al realizar otra apuesta y se usa la camisa roja? ¿Y otra vez?
Lo que tendría que hacer es mirar el patrón más amplio de eventos, si los eventos del primer tipo se unen constantemente con eventos del segundo tipo. Y aquí no tenemos derecho a hacer ninguna presunción sobre lo que es una coincidencia. En otras palabras Home diría, la causalidad es, a este respecto, una relación totalmente contingente. No hay contradicciones en dos tipos de eventos distintos, ya sean relacionados causalmente o no relacionados causalmente. Podría pensar que sería poco probable que una cosa siguiera a otras muchas veces si fuera pura coincidencia. Eso puede ser cierto, pero Home realmente no puede afirmarlo, se ha pintado a sí mismo en una esquina donde tiene que decir que si A siempre es seguido por B, entonces, A causa B. La teoría implica esto, podría dejar una pregunta abierta. ¿En todos los casos en los que A es seguido por regularidades de B, para cualquier cosa A y B, algunos serán casos de causalidad, tal vez la mayoría de ellos, pero algunos podrían ser accidentales? Se necesita una forma más sofisticada que la que usa Home, si se trata de hacer esta distinción.
Si uno piensa en el tema de las causas y las coincidencias, saca a la luz un resultado aparentemente contradictorio y paradójico de la teoría de la regularidad de Home[10]. Será más fácil que se produzca una conjunción constante accidental cuantas menos instancias tenga. Si A ocurre solo cinco veces en la historia del mundo y es seguida por B en cada ocasión, que podría ser una coincidencia que los humanos funcionemos así por un causal. Home tendría que admitir que las regularidades, por lo tanto la causalidad, es más probable cuantos menos casos haya de la causa. Esto parece paradójico porque normalmente pensaríamos que es más probable que A sea una causa de B cuantos más casos haya de A seguidos de B.
Hay una versión extrema de este problema. ¿Qué sucede si solo hay una única instancia de A? Por ejemplo, supongamos que hay un universo que contiene solo dos eventos, hay una explosión y luego un resplandor de luz. Ahora la pregunta es ¿el Bin Bang causó el resplandor? Si uno sigue un conteo de conjunción constante, parece que uno tiene que decir que sí. El Bang es causal del resplandor siempre, en todos los casos. Pero aún podemos decir que podría ser una mera coincidencia.
Hay que añadir con justicia a Home que él tiene una respuesta a este tipo de objeción. Al discutir si Dios podría haber causado la existencia del universo, en un acto de creación, argumenta que esto nunca podría contar como causalidad. La razón es que este es un evento totalmente único e, insiste, es la repetición lo que nos hace formar nuestra idea de causa. Así que para Home creer en Dios como el que causó el universo, él querría saber cuántas veces es suficiente, pero la idea general es que deberíamos estar más convencidos de que la causalidad ha ocurrido cuanto más casos de su conjunción vemos, en lugar de cuantos menos casos vemos. Eso ciertamente parece un juicio de una parte que es coherente con el sentido común.
Ahora tenemos lo básico en lugar de una visión de regularidad de Home. Las regularidades no son todo lo que necesitamos para decir que una cosa causa otra. Pero la regularidad es una parte importante de la noción de causa. Y hay que reconocer que en muchas ciencias estamos buscando principalmente correlaciones. Si un ensayo muestra que la tasa de recuperación de una enfermedad mejora con un medicamento, ¿no es suficiente para que pensemos que alguna causalidad está en el trabajo?
A veces se desalientan los que trabajan en las ciencias al preguntar si hay una causalidad “real” detrás de la correlación. Tal vez sea más que la sospecha de metafísica (lenguaje) lo que está detrás de esto. Tal vez también hay una opinión de que la correlación es todo lo que hay. ¿No debemos esperar nada al acecho detrás de la correlación, produciendo la regularidad? Veremos, sin embargo, que hay una serie de otras cuestiones que abordan la causalidad y otras teorías de la causalidad que podrían resultar más atractivas.
Home se dio cuenta de que había más en nuestra idea de causalidad que la simple correlación. Que dos fenómenos que se unen regularmente no serían suficientes por si solos para darnos una idea de causal. Cada vez que nace un niño, sabemos que está correlacionado con un óvulo que se fertilizó, generalmente después del coito. Pero el nacimiento del niño no causó el coito. Eso hace que las cosas se equivoquen de dirección al sacar conclusiones.
Pensó Home, dos ideas más están involucradas; además de la conjunción constante, Home pensó que nuestra noción de causa incluía las ideas de prioridad temporal y contingencia. La prioridad temporal significa que las causas deben preceder a sus efectos en el tiempo. La contingencia significa que las causas y efectos deben estar en lugares uno al lado del otro (en contacto físico de fuerzas, más…). Existe un atractivo intuitivo en la idea de que tanto prioridad temporal y contingencia son necesarias para una idea de causalidad. Pero vemos que no solo se puede desafiar a ambas, sino que las dos condiciones también están en tensión: una socava a la otra.
Debemos tener en cuenta que el argumento de Home sobre la causalidad se produce en un contexto de epistemología empírica. Su preocupación es con cuál es nuestra idea de causa y de dónde vino. Si no podemos mostrar ninguna impresión de sentido original o la serie de tales impresiones de sentido original de dónde obtuvimos una idea, entonces Home piensa que es ilegítimo y debe ser rechazada la idea.
Esto plantea todo tipo de cuestiones de interpretación filosófica: sobre si podemos pensar en algo que no sea nuestra propia experiencia. Hay, sin embargo, algunas preguntas importantes por hacer a cerca de la causalidad, que no son solo preguntas sobre nuestro concepto de causa.
¿Qué es tan atractivo acerca de la prioridad temporal? Nuestra experiencia parece mostrarnos que las causas son lo primero y los efectos un tiempo después. El teclado se golpea primero y luego se imprimen los signos; se toma un fármaco y luego el dolor de cabeza se va; la difamación se hace primero y luego la reputación se daña. Y partir de esto, podemos utilizar el orden temporal de los efectos cuando hay una regularidad.
Supongamos que íbamos a encontrar que la gente feliz tiende a ser amable. Hay una correlación entre la felicidad y la amabilidad. Podríamos decidir que existe una relación causal entre estos dos factores, pero ¿cuál fue la causa y cuál fue el efecto? Una manera sensata de resolver esto sería investigar que es lo primero. ¿Estas personas fueron felices primeros y luego se hicieron amigables? ¿O primero fueron amigables y luego se volvieron felices? Esto no resolvería el asunto de manera concluyente, pero podría ser una buena guía.
También se podría ver de esta manera. Supongamos que la autoridad acusa a un fabricante de estar enfermando a varios de sus empleados a través de la exposición a alguna sustancia sin una protección adecuada. ¿Qué argumento podría producir una defensa si pudiera demostrar que cada empleado tenía la enfermedad en la misma gravedad de la causa alegada desde antes?, entonces esto parece descartar automáticamente la causalidad.
Cuando aceptamos que las causas son temporales anteriores a sus efectos, algo útil sale de ellas. Si A causó B, entonces B no causó A. La aceptación de la prioridad temporal podría explicar esta asimetría. Si A causó B, y las causas deben ser anteriores a sus efectos, entonces se deduce que A es antes de B. De ello se deduce una vez más que B no puede, por lo tanto, estar antes de A; y por lo tanto que B no puede ser una causa de A.
La prioridad temporal proporcionaría una asimetría a la causalidad que ni la conjunción constante ni la contigüidad podrían proporcionar. Todavía tenemos que examinar la contigüidad, pero la conjunción constante no haría el trabajo por la siguiente razón. Si bien un A constantemente unido con B no implica que B se una constante con A, tampoco lo excluye. Es posible, por ejemplo, que todos los que están contentos sean amables, pero también que todos los que son amables son felices. Técnicamente hablando, clasificaríamos la conjunción constante como una relación no simétrica (una relación simétrica es aquella que se mantiene en B, entonces B tiene que mantenerla en A, como donde A es la misma altura que B).
Esta prioridad temporal asimétrica parece muy importante para nuestra noción de causalidad. Añade algo crucial a la regularidad. Le da una dirección. Volvamos ahora a la contigüidad. La opinión de Home fue que si A y B están constantemente unidas y A ocurre antes de B, entonces esto todavía no sería suficiente para que concluyamos que A es una causa de B. La razón de esto es que A y B también tendrían que estar una al lado de la otra; es decir, espacialmente adyacentes. Esto es lo que Home quiere decir con contigüidad.
Consideremos un ejemplo mundano una vez más. Podemos suponer que hay una regularidad entre las partes que se golpean y la iluminación de esa parte. Ahora hemos añadido que para afirmar que el golpe hizo que se encendiera la luz, debemos decir que el golpe ocurrió antes de la iluminación. Pero, ¿Cuál es el siguiente escenario elegante? Creemos que la causalidad no ocurre a distancia, no inmediatamente, en cualquier caso. La causa de la iluminación, cuando se golpea debe estar en el mismo plano. Del mismo modo, para que una bola de billar haga a otra moverse, debe tocarla, debe ocupar el siguiente lugar disponible para la pelota que se mueve. Y para que una persona se enferme de una bacteria, la bacteria debe entrar en contacto con ella. No se puede estrangular a alguien sin tocarlo, o no puede comer a distancia alguien sus alimentos.
En todos estos casos, parece plausible que la causa funcione sobre el efecto a través de una cadena de causas y efectos intermedios, donde cada uno de estos eslabones de la cadena de causas y efectos intermedios, implica una acción contigua. No pasa directamente de uno al otro, en cada uno de estos casos podemos encontrar que la causalidad ha viajado de un lugar a otro por efectos de puntos intermedios. La idea de cadena causal es importante. Las causas pueden alinearse en una fila y seguir una tras otra, creando efectos en un momento mucho más tarde y en lugares distantes. Una forma muy sencilla de imaginarlo es lo que sucede cuando alineamos ficha de dominó. Derriba la primera, golpeando a una segunda y así todas caen a su vez. Es fácil hacer esto y divertido de ver, porque llegamos a ver una cadena causal extendida. El golpe de la primera pieza provoca la caída de la última, alguna tiempo después y a cierta distancia. Podemos ver cómo lo hace a través de una serie de transacciones causales individuales.
Una cadena causal. Si bien vemos que hay un atractivo intuitivo a la noción de que las causas deben preceder a sus efectos, también plantea un problema. ¿Cómo puede una causa afectar algo a menos que exista al mismo tiempo lo que la afecta? Esto sugiere que la causalidad ocurre en el momento en que dos cosas entran en contacto, donde el impulso se pasa de una a otra. No puede ocurrir antes del contacto ni después de haberse separado, de acuerdo con la demanda de contigüidad.
Simultaneidad. La discusión anterior es un desafío a la afirmación de Home de que las causas deben preceder a sus efectos. Home parecía pensar que esto era parte del concepto mismo de causa. Pero, si se equivoca, ¿qué podríamos decir en su lugar? Una opción, sugerir que para el caso del billar, es decir que las causas y los efectos son simultáneos. Esto nos permitiría conservar el otro compromiso de Home con la contigüidad. Kant, pensó que la idea de causalidad simultánea era creíble. Ahora Home había dicho, por supuesto, que la prioridad temporal era parte de la noción misma de causa. Si tenía razón en esto, ni siquiera podríamos considerar la idea de causalidad simultánea. Sería como una contradicción en sus términos. Pero dado que hay ejemplos perfectamente coherentes, entonces parece más probable que Home estuviera equivocado. La casualidad simultánea es al menos concebible y algunos ejemplos sugieren que es incluso parte de la realidad. Y para reforzar el punto, algunos encuentran que los viajes en el tiempo hacia atrás son concebibles y eso sugiere que las causas podrían ocurrir después de sus efectos.
Supongamos que un viajero del tiempo aparece en una máquina del tiempo en 1984, pero su aparición fue causada por él movimiento de un interruptor en su máquina del tiempo de 2020. Una vez más, esto parece concebible, incluso si es una fantasía de ciencia ficción, por lo que Home podría estar esquivocado de que la prioridad de causa sobre efecto es esencial para la causalidad. Vale la pena señalar, sin embargo, que el argumento de la simultaneidad de causa y efecto, trabaja en contra de cualquier división temporal de causa y efecto, sin importar la dirección de la causalidad. El verdadero problema en el caso del viaje en el tiempo parece ser el salto directamente de una vez a otra. El hecho de que las causas y los efectos pueden ocurrir simultáneamente no significa que ocurran instantáneamente. Algunas causas tienen su efecto durante un largo periodo de tiempo.
Sin embargo, por lo que se podría decir es que cada eslabón de una cadena causal implica solo la simultaneidad de causa y efecto, algunos de los cuales implican procesos temporales extendidos. Por lo tanto, la cadena causal puede llevar tiempo. Y el punto final de cada eslabón de la cadena podría solaparse con el siguiente eslabón de la cadena, existente al mismo tiempo que su vecino. Algunos de esos relatos podrían conciliar la simultaneidad con las cadenas causales temporalmente extendidas.
No debemos asumir que la noción de contigüidad de Home tampoco es indiscutible. Una vez más, hay un argumento de que se equivocó al insistir en ello como una verdad conceptual.
Los físicos explican casos en entrelazamiento cuántico. Aquí es donde las propiedades de las partículas se ven conectadas, de modo que una medición en una partícula parece garantizar el resultado de una medición en otra. Lo que está desafiando sobre el caso es que esto se mantiene inmediatamente e independientemente de la distancia. Supuestamente, cuando se mide una partícula, entonces su compañera gemela entrelazada, no importa cuán lejos, debe tener un cierto valor en ese mismo momento. La física todavía está tratando de interpretar exactamente lo que está pasando en estos casos, pero una interpretación, implica acción instantánea a distancia, sin ninguna cadena intermedia. Esto sería profundamente desconcertante porque parece implicar la causalidad viajando más rápido que la luz, que supuestamente es lo más rápido de todas las cosas.
Aparte de eso, sin embargo, lo que significa es que parece que somos capaces de concebir que la causalidad ocurre no localmente, es decir, sin contigüidad. Así que la prioridad temporal como la contigüidad pueden ser desafiadas.
Cuando la causalidad está en juego, el efecto es más que una mera posibilidad entre muchas otras. Hay una buena razón por la que se produce el efecto específico. Causas, se piensa, obliga o hace que sus efectos sucedan. Cuando el azúcar está en el café caliente debe disolverse; cuando una bola es golpeada debe moverse; cuando una cosa es lanzada hacia arriba debe caer en algún momento y cuando un organismo tiene una cierta estructura orgánica, debe desarrollarse de cierta manera.
Lo que muchos consideran que falta de una visión de regularidad causal, incluso si va acompañada de contigüidad y prioridad temporal, es un sentido de necesidad de las causas. El efecto no es un accidente, dada la ocurrencia de la causa. En su lugar, la causa se considera totalmente suficiente para que produzca el efecto. La filosofía de Home, que es pensada por muchos, contiene demasiada contingencia. Es un mosaico que sugiere que cualquier cosa podría seguir cualquier cosa. Pero por supuesto que rechazamos esto último. Consideramos que la causalidad, es genuinamente de sus efectos en un sentido más fuerte de lo que Home permite. ¿Qué queremos decir con necesidad y contingencia? Los filósofos tienen diferentes maneras de conceptualizar estas dos opciones. Por necesidad, pueden significar que algo está estrictamente implicado, que tiene que ser el caso, o que es cierto en algunos mundos, pero no en todos los posibles. Se puede pensar que es necesario que 5+3 =8, pero contingente como que Morelia es la capital de Michoacán, México. Pero no hay ninguna posibilidad en lo absoluto dentro de ese sistema aritmético que 5 + 3 no podría ser diferente de 8.
¿Es necesario que el agua sea H2O, que la velocidad de la luz sea un límite cosmológico, o que un electrón sea de carga negativa. Y dentro de estas categorías discutidas, podemos poner causas. ¿Es una cuestión de necesidad? Home consideró a la necesidad como un posible cuarto elemento de la idea de causa, junto con las tres ideas ya discutidas de regularidad, prioridad temporal y contingencia espacial. Admitimos que la necesidad es a menudo parte de la comprensión común de la causa. Filosóficamente, sin embargo, llegó Home a la conclusión de que no tenía un lugar legítimo.
Su argumento era que un solo caso de causalidad no nos revela ninguna evidencia de necesidad. La opinión de Home es que solo vemos una sucesión de eventos: una cosa después de otra. Nuestra idea de causa viene de ver una repetición del mismo tipo de secuencia de evento. Esto forma en nosotros una perspectiva de que otros casos serán como los que hemos ya visto. Pero no hay necesidad de que así sean. Si un solo caso no muestra ninguna necesidad, entonces no puede provenir de solo otras instancias del mismo. Cada caso no contiene nada más que contingencia; ninguna cantidad de contingencia adicional nos lleva a la necesidad. Eso sería como esperar que las condiciones del número cero eventualmente nos llevarán a uno.
3.4 ¿Qué es la reproducibilidad?
Un experimento de laboratorio es reproducible cuando experimentos posteriores, por los mismos o diferentes científicos, confirman los resultados. Los términos repetibilidad y replicabilidad a veces se utilizan indistintamente o con significados relacionados, pero usaremos la reproducibilidad como término que abarca a todos. La reproducibilidad puede ocurrir en varios niveles:
La reproducibilidad analítica o computacional se refiere a la obtención de los mismos resultados utilizando los datos originales y una descripción del análisis. Este es un estándar mínimo, pero es imposible de lograr cuando los datos no están disponibles. Incluso si los datos son proporcionados en el material complementario o en las bases de datos públicas, la reproducción de los resultados puede ser difícil si la descripción del análisis es incompleta[11]. Un requisito mínimo para la reproducibilidad analítica es proporcionar los datos subyacentes a los resultados y los scripts que los produjeron. Esto es sencillo cuando se utiliza R porque el código se puede integrar en documentos como informes y publicaciones. Por ejemplo, grandes partes de este curso tienen códigos R incrustado, que se evalúa y las salidas se insertan en el texto.
La reproducibilidad directa se refiere a obtener los mismos resultados utilizando las mismas condiciones experimentales, materiales y métodos que el experimento original. El objetivo es hacer que el segundo experimento sea lo más similar posible al original, lo que requiere una descripción adecuada de cómo se llevó a cabo el experimento original. La replicación directa es el foco de interés en la formación universitaria, pero puede que no esté claro de inmediato cómo mejores diseños experimentales pueden mejorar la reproducibilidad directa. La respuesta breve es que un experimento bien diseñado puede influir en el resultado, replica el aspecto correcto del experimento y puede generalizar los resultados a otras condiciones, lugares y muestras.
La reproducibilidad sistemática se refiere a la obtención de los mismos resultados, pero en diferentes condiciones; por ejemplo; utilizando otra línea celular o cepa de ratón, o inhibiendo un gen farmacológicamente en lugar de genéticamente. Las razones de la falta de reproducibilidad sistemática son más difíciles de determinar porque las líneas celulares pueden ser diferentes, y lo que funciona en uno no funcionará en otro. Esto no debe tomarse como evidencia de malas prácticas de investigación, una función de los estudios posteriores es encontrar las condiciones bajo las cuales se mantiene un hallazgo inicial. El diseño experimental también puede ayudar aquí, ya que los estudios iniciales pueden diseñarse para abordar la cuestión de la generalización desde el principio.
La reproducibilidad conceptual se refiere a obtener los mismos resultados generales en diversas condiciones, donde el objetivo es demostrar la validez de un concepto o un hallazgo utilizando otro paradigma. El concepto o hipótesis general podría ser “el estrés inhibe la formación de la memoria”, que podría probarse en un experimento donde la gente memoriza pares de palabras con música fuerte y en otro experimento donde las ratas aprenden la ubicación de los alimentos después de una inyección de corticosterona (hormona del estrés). Hay muchas razones válidas por las cuales algunos experimentos apoyan la hipótesis y otros no, tal vez la corticosterona, mientras que participa como respuesta al estrés, es irrelevante para el aprendizaje. Discrepancias entre los resultados de experimentos no necesariamente indican mala reproducibilidad.
Un resultado reproducible se definió como uno confirmado por experimentos posteriores, pero ¿qué significa confirmado? Una idea es que si el experimento original tiene un valor p inferior al 0.05, el experimento se confirma si el experimento posterior también tiene un valor p significativo. Aunque este criterio parece plausible, tiene varios problemas. En primer lugar, un estudio con un valor p de 0.03 se consideraría irreproducible si el experimento posterior tuviera un valor p de 0.08. Pero para todos los efectos prácticos, los estudios pueden tener los mismos tamaños de efecto y sus dos intervalos de confianza (CI) pueden suponerse sustanciales. Esta relación se muestra en la figura 3.1 entre el experimento original y el segundo experimento, Nuevo 1. Un segundo problema es que este enfoque omite el tamaño de la muestra y la potencia de los experimentos. Supongamos que se realizó un análisis de potencia basado en los resultados experimentales originales y el experimento de seguimiento utiliza un tamaño de muestra ligeramente más pequeño y, por lo tanto, los intervalos de confianza serán ligeramente más anchos, suponiendo que todo lo demás sea constante (Nuevo 2). Aunque el tamaño del efecto para Nuevo 2 es mayor que el original, Nuevo 2 no habría reproducido las conclusiones originales según este criterio. Un tercer problema es que un estudio de seguimiento puede tener un tamaño de efecto diferente al original pero se consideraría que ha reproducido con éxito el original si el valor de p es significativo. Esta situación se muestra para el experimento Nuevo 3, donde el 95% de los CI no se superponen con el experimento original. No hay criterios acordados para cuando se puede decir que un experimento reproduce otro, pero dentro de un campo, los científicos “los saben cuando lo ven”.
 18.11.55.png)
Figura 3.1 Tamaños de efecto para un experimento original y tres de seguimiento, utilizando la significancia (CI) como criterio de reproducibilidad.
3.5 La psicología del descubrimiento científico
Es poco común que para la educación de un científico se discutan aspectos de psicología de la investigación, pero las investigaciones científicas no se llevan a cabo en el vacío; tienen lugar en el contexto de investigaciones previas; son llevadas a cabo por personas que prefieren ciertos resultados sobre otros y, están limitadas por las normas y convenciones utilizadas por grupos de investigación y la comunidad académica en general. Las expectativas y deseos del investigador, además, de las presiones externas para publicar y demostrar creatividad e innovación, influyen en la forma en que los datos se analizan, interpretan e informan. Esto debe ser reconocido y discutido porque mejorar la reproducibilidad y hacer realidad la investigación, es el objetivo para mejorar las habilidades matemáticas de los científicos[12].
Algunos de los temas que se tratan a continuación se enmarcan en el campo de la investigación psicológica de la heurística y los sesgos. Los sesgos cognitivos (corrupción de la razón) o las ilusiones cognitivas son desviaciones de las respuestas verdaderas u óptimas al hacer estimaciones, inferencias, decisiones, conclusiones o juicios[13]. Son cognitivos en el sentido de que son el resultado de procesos perceptivos, emocionales y presiones sociales y no consecuencia de errores de dispositivos mal calibrados para su medición. También son sistemáticos, lo que significa que las desviaciones tienden a estar en una dirección determinada. También son difíciles de evitar. Los sesgos cognitivos pueden influir en el diseño, análisis, interpretación e informes de experimentos biológicos y, por lo tanto, son relevantes para las investigaciones clínicas, de alimentos, fármacos…, en lo particular.
3.5.1 Ver patrones en la aleatoriedad
Las personas a menudo ven patrones donde no existen, incluidos clústeres, asociaciones entre variables y secuencias de valores similares. En la figura 3.2 se muestra un ejemplo. Las posiciones de latitud y longitud de 100 bombas lanzadas en la segunda guerra mundial, se muestra para dos ubicaciones geográficas diferentes. En general se quiere saber si el enemigo está lanzando bombas al azar, o si están apuntando a ciertas posiciones más fuertemente y se pide investigar. La inteligencia de la línea del frente indica que si el enemigo está usando una estrategia aleatoria, probarán aleatoriamente un par de coordenadas de latitud y longitud con la misma probabilidad en cualquier lugar dentro de la región de bombardeo, conocida como estrategia uniforme de bombardeo aleatorio. ¿Fue una estrategia uniforme de bombardeos aleatorios la utilizada en cualquiera de las ubicaciones de la Figura 1.2? Si es así ¿cuál? Además, ¿hay pruebas en ambos lugares para que determinadas posiciones sean bombardeadas más frecuentemente mientras otras se evitan, lo que posiblemente refleje la importancia táctica de las posiciones?
Muchos dirían que la distribución de puntos en la ubicación 2 representa la estrategia de elegir aleatoriamente una latitud y una longitud de una distribución uniforme de la geografía. Las posiciones de la ubicación 2 se generaron en su lugar seleccionando una cuadrícula de 10 por 10 de posiciones igualmente espaciadas y, a continuación, agregando algo de ruido a estos valores. Esto hace que las posiciones de la bomba estén uniformemente espaciadas. La estrategia uniforme aleatoria solo se utiliza en la ubicación 1. Esto parece contraintuitivo porque hay regiones grandes sin bombas, mientras que otras regiones tienen una agrupación más densa. Estas regiones agrupadas y vacías son las que se espera bajo una estrategia aleatoria uniforme. La intuición sobre como se ve la alatoriedad no viene fácil o naturalmente.
 20.14.47.png)
Figura 3.2 Dos ubicaciones.
3.5.2 No querer perderse nada
Los patrones potencialmente significativos como el ejemplo anterior se pueden probar formalmente con un análisis estadístico, pero es importante evitar el uso de los mismos datos para encontrar primero un patrón interesante (como la región vacía inferior izquierda de la ubicación 1 en la figura 3.2). Y a continuación, probar estadísticamente este patrón. Por ejemplo, podríamos intentar calcular la probabilidad de que no caigan bombas en una área del tamaño de la región inferior izquierda vacía. Los datos aleatorios, especialmente cuando hay muchos de ellos, tendrán regularidades y patrones locales. Elegir uno de estos patrones que nos llama la atención y luego realizar una prueba estadística, en el sentido de que todos los patrones que podrían haber sido interesantes fueron examinados y descartados sin una prueba formal. Por ejemplo, no parece que se lanzaron más bombas en latitudes más altas en comparación con latitudes más bajas (comparando la parte superior frente a la mitad inferior de la ubicación 1). Si tal patrón pareció existir, entonces lo probaríamos en su lugar. El principio clave, es ver si una hipótesis se deriva de datos, entonces la capacidad de los datos para apoyar esa hipótesis se reduce. La capacidad de los datos para apoyar una hipótesis también puede verse comprometida por lo que hacen los demás. Por ejemplo, un estudiante es la primer persona en analizar un conjunto de datos y los explora a fondo. Encuentra una relación, pero no está seguro de la prueba estadística apropiada, por lo que la pone en conocimiento del investigador principal. A continuación, el investigador realiza un solo análisis y se siente seguro de que el valor p es válido, ya que no es consciente de cómo se utilizaron los datos para descubrir esta relación.
Incluso cuando una inspección visual de los datos no es tan pronunciada, las personas quieren aprovechar al máximo los datos y evitar perderse nada interesante. Este deseo es probablemente mayor cuando el resultado principal no es significativo y luego tenemos que ver qué más podemos obtener de los datos. Uno podría comenzar a buscar correlaciones entre variables, luego rebuscar de nuevo después de normalizar o corregir otras variables. A continuación, comprobar si hay diferencias entre los sexos, las edades altas frente a los jóvenes, o los menos gravemente afectados en comparación con los más afectados, y así sucesivamente hasta que haya suficientes hallazgos interesantes para informar. Por un lado, parece absurdo no examinar a fondo los datos, dado todo el trabajo que se hizo para generarlos. Por otro lado, un proceso de búsqueda de este tipo puede generar muchos falsos positivos.
Hay dos enfoques para limitar el número de resultados falsos positivos que surgen de los descubrimientos basados en datos. El primero es dividir los análisis en partes confirmatorias y exploratorias. El análisis confirmatorio especifica todo por adelantado (antes de ver los datos), incluida la hipótesis a probar, la variable de resultados principal y el análisis que se utilizará. El análisis exploratorio posterior permite una mayor flexibilidad para encontrar otras relaciones de interés, pero con el conocimiento de que los hallazgos tienen menos peso y son menos convincentes porque no se predijeron de antemano, incluso si se hallazgos intentado corregir para múltiples pruebas. El segundo enfoque consiste en validar los hallazgos, ya sea mediante la realización de un experimento posterior o dividiendo los datos en dos partes una vez completado el experimento, pero antes de cualquier análisis, alrededor del 20-30% de los datos se eliminan y bloquean. Los datos restantes se utilizan para encontrar relaciones interesantes. Una vez completado el análisis, los datos que se bloquearon se utilizan para confirmar los hallazgos. Este es un enfoque común en los campos de minería de datos, aprendizaje automático y modelado predictivo, pero requiere suficiente muestras para dividirse en dos conjuntos.
Las personas difieren en la facilidad con la que detectan señales en el ruido puro, encuentran patrones en la aleatoriedad o significado en la coincidencia. Un signo de madurez inferencial en una persona, es saber dónde se encuentra en el espectro del manejo de la lógica necesaria para evaluar la verdad. Si encuentra algo vagamente parecido a una asociación o efecto interesante en lugar de tender a verlo como real, su atención la enfoca en el control de falsos positivos, es una actitud escéptica para no correr el riesgo de quedarse fuera de los verdaderos hallazgos de conocimiento.
3.5.3 El acantilado psicologico de p =0.05
Una critica a los valores p es que fomentan el pensamiento dicotómicamente (el efecto o la relación es significativo o no lo es) a pesar de que la evidencia es continua. En la década de 1960, Rosenthal y Gaito demostraron que tal efecto psicológico existe. Los sujetos tienden a tener una confianza lineal o de disminución exponencial al aumentar el valor de p[14]. La diferencia entre significativo y no significativo no es en sí misma una idea estadística. Se refiere a una situación en la que, por ejemplo, el grupo A es significativamente diferente del grupo de control, el grupo B no es significativamente diferente del grupo de control, y luego se hace una conclusión incorrecta de que el grupo A es significativamente diferente del grupo B. Si las diferencias entre los grupos A y B son de interés, entonces deben comparase directamente entre sí.
En la medida en que un pequeño valor de p proporciona evidencia para una hipótesis de investigación, no existe una distribución probatoria aguda entre 0.04 y 0.06. Una pregunta obvia es ¿cuál es la relación correcta entre el valor de p y la evidencia de una hipótesis? La respuesta corta es que no hay una relación correcta porque un valor p no dice nada sobre la hipótesis y por lo tanto la pregunta no tiene sentido. Si usted está interesado en la evidencia o la probabilidad de que una hipótesis sea correcta, entonces se requieren métodos de probabilidad bayesiana.
El punto clave es que no hay nada especial sobre 0.05 o valores en ambos lados, indica un cambio abrupto en lo que los datos tienen que decir sobre una hipótesis. Gelman y Loken plantearon dos puntos relacionados sobre la interpretación de resultados estadísticos[15]. La primera interpretación es que los efectos no pueden dividirse en los que son reales y los que no son reales, basados en un valor p. La presencia y magnitud de los efectos y asociaciones están condicionadas a el material de muestra utilizado; también, las variables y condiciones de fondo tales como tecnologías y experimentos; el diseño experimental es un factor de bloqueo incorporado como lo son el preprocesamiento de datos y el análisis estadístico. Dada la magnitud de un efecto o asociación simple está condicionada a tantos efectos o asociaciones varía en diversas situaciones. En algunas condiciones el efecto puede ser menor y el valor p por encima de 0.05, y esto no indica una falta de reproducibilidad.
Wikipedia al respecto dice[16]:
En estadística general y contrastes de hipótesis, el valor p (conocido también como p, p-valor, valor de p consignado, o directamente en inglés p-value) se define como la probabilidad de que un valor estadístico calculado sea posible dada una hipótesis nula cierta. En términos simples, el valor p ayuda a diferenciar resultados que son producto del azar del muestreo, de resultados que son estadísticamente significativos.
Si el valor p cumple con la condición de ser menor que un nivel de significancia impuesto arbitrariamente, este se considera como un resultado estadísticamente significativo y, por lo tanto, permite rechazar la hipótesis nula.
 20.21.09.png)
Es fundamental reforzar que el valor p está basado en la presunción de que una hipótesis nula (o hipótesis de partida) es cierta. El valor p es por tanto, una medida de significación estadística. El valor p es un valor de probabilidad, por lo que oscila entre 0 y 1. El valor p nos muestra la probabilidad de haber obtenido el resultado que hemos obtenido suponiendo que la hipótesis nula H0 es cierta. Se suele decir que valores altos de p no permiten rechazar la H0, mientras que valores bajos de p sí permiten rechazar la H0.
El segundo punto es que el análisis estadístico no determina si un efecto es real, así como los microscopios no determinan si las bacterias son reales, pero tanto microscopios como las estadísticas pueden ayudar a ver cosas que no son obvias a simple vista. Los efectos son determinados por el proceso biológico bajo investigación, el experimento utilizado para sondearlo y los datos derivados de él. Ocasionalmente, los efectos son tan grandes y claros que no es necesario ningún análisis estadístico. Cuando el experimento es más complejo y los resultados son menos obvios, un análisis estadístico solo ayuda a interpretar lo que ya existe. La interpretación de los resultados puede definirse dependiendo del análisis, pero también pueden definir una conclusión sobre un fenómeno dependiendo del microscopio (luz focal o electrónico). No creemos un resultado solo porque las estadísticas lo dicen.
3.5.4 El descuido de la variabilidad del muestreo
La variabilidad del muestreo es la razón por la que el resultado de un proceso aleatorio difiere entre ejecuciones. Si una moneda justa es lanzada 10 veces, esperaríamos, en promedio, cinco caras y cinco cruces. En un juicio dado podemos tener más o menos caras, pero esperaríamos que la mayoría de los lanzamientos tuvieran entre dos y ocho caras. En otras palabras, la proporción de caras es de 0.5, con la mayoría entre 0.2 y 0.8. Eso es variabilidad de muestreo, dado que no siempre obtenemos cinco caras y cinco cruces. Además, a medida que aumenta el tamaño de la muestra, disminuye la variabilidad en el resultado. Cuando el tamaño de la muestra se aumenta a 100 lanzamientos, todavía esperamos que la proposición de caras sea 0.5, pero ahora la mayoría estará entre 0.4 y 0.6, un intervalo más estrecho. Esta es la dependencia del tamaño de la muestra: cuando mayor sea el tamaño de muestra, más estrecho será el intervalo de de valores que es probable que veamos. A medida que aumenta el tamaño de la muestra, convergemos a la verdadera proporción de caras del lanzamiento de una moneda justa. Estas ideas simples aparecen a menudo y pueden conducir a inferencias y conclusiones incorrectas si se tienen en cuenta.
Este fenómeno de mayor varianza con tamaños de muestra más pequeños también es relevante para experimentos biológicos. Un ejemplo, ocurre cuando se clasifican los compuestos activos de acuerdo con la razón por la que el compuesto fue seleccionado para su inclusión en el ensayo[17]. Algunos compuestos se seleccionan para las pruebas porque se unen a proteínas en una vía bioquímica que se cree que es relevante para la enfermedad. Alternativamente, los mecanismos epigenéticos pueden ser importantes y por lo tanto se incluye cualquier compuesto que se sabe que afecta a la metilación del ADN o la acetilación de histona[18]. Además, un conjunto de compuestos químicos diversos se utilizan a menudo para cubrir una amplia gama del espacio químico. Al final suele ser de interés ver si uno de los tres conjuntos de compuestos (compuestos de vías, epigenético o diversos) se enriquece para lograr dar en el blanco. Pero no sería sorprendente para el conjunto epigenético tener un porcentaje inusualmente alto o bajo de aciertos si contenía solo 50 compuestos, mientras que el conjunto de vías tenia 5000 y el conjunto diverso 50,000. Por lo tanto, el porcentaje de aciertos no proporciona suficiente información para sacar conclusiones sobre los conjuntos compuestos. ¿Se puede pensar que experimentos de este tipo la variabilidad del muestreo podría proporcionar una interpretación diferente de los resultados?
La variabilidad del muestreo también es importante a la hora de evaluar la reproducibilidad de los resultados. Algunos investigadores se sorprenden cuando obtienen resultados diferentes después de repetir un experimento, especialmente cuando se gastó un gran esfuerzo para hacer que la replicación sea lo más similar posible al experimento original. Los “resultados diferentes” se definen generalmente como uno con p<0.05 y otro con p>0.05. Es imposible reproducir exactamente un experimento, pero incluso si fuera posible, los resultados no serían idénticos debido a la variabilidad del muestreo. Al igual que tirar una moneda 10 veces da un número diferente de caras cada vez, la estimación de la diferencia entre dos grupos dará una estimación diferente cada vez que se lleva a cabo el experimento. Las grandes diferencias de importancia se pueden asociar con pequeñas diferencias en el efecto subyacente.
3.5.5 Sesgo de independencia
El sesgo de independencia es la tendencia a sobreestimar el valor probatorio de los nuevos datos, especialmente cuando los datos están correlacionados con los datos existentes. Conduce a creencias de que muchos resultados significativos proporcionan un apoyo mucho más fuerte para una hipótesis de lo que realmente lo hacen. Supongamos que estamos interesados en aumentar la fuerza muscular en los seres humanos. Asignamos al azar 20 personas al grupo de control compuesto o placebo y evaluamos su fuerza después de 4 semanas de tratamiento. La fuerza de los sujetos se mide en tres ejercicios: prensa de banco, levantamiento peso y sentadillas. Las tres variables de fuerza tienen los siguientes valores p al probar el efecto del compuesto: p=0.01, p=0.03 y p=0.02. ¿Qué tan convincentes son los resultados? ¿Qué tan probable es que los tres valores p serían significativos si el compuesto estuviera inactivo? Muchas personas razonan informalmente que aunque hay una probabilidad de 0.05 de un resultado falso positivo, tres resultados significativos proporcionan evidencia convincente para el efecto del compuesto, incluso si los valores p no son muy pequeños. Formalmente, si hay una probabilidad de 0.05 de un resultado falso positivo, la probabilidad de tres falsos positivos es p=0.05x0.05x0.05=0.05^3=0.000125. Puesto que esta probabilidad total es pequeña, es poco probable que las tres pruebas sean significativas si el compuesto está inactivo.
El sesgo mental surge porque los tres resultados medidos no proporcionan información independientemente sobre el efecto del compuesto. La probabilidad total calculada solo es válida si los tres valores p son independientes, lo que ocurriría, por ejemplo, si los valores fueran de tres experimentos diferentes utilizando personas diferentes. En el otro extremo, si los tres resultados medidos están perfectamente correlacionados, entonces todos serían significativos o ninguno de ellos, el segundo y tercer valor p no proporcionan ninguna nueva información una vez que contó el primero. Cuanto mayor sea la correlación entre las variables, mayor será la redundancia en la información proporcionada.
Las tres variables de este ejemplo están altamente correlacionadas porque miden lo mismo: fuerza física. La fuerza, como muchos aspectos de la biología, es difícil de definir y a menudo no se puede medir directamente, así como otros casos como la inflamación, estado de enfermedad, funcionamiento cognitivo, estados psicológicos y emocionales, e incluso expresión genética. Estos no se observan o miden directamente como el peso de una persona. A las variables que no se pueden medir directamente se denominan variables latentes. El caso de la variable peso de una persona, se le llama variable observable.
Las variables altamente correlacionadas no proporcionan pruebas independientes de un efecto porque a menudo son medidas diferentes de un único efecto subyacente. El ejemplo anterior utilizado para medir la fuerza física, el mismo problema surge con con la expresión de genes, proteínas o implicación de las vías metabolicas, ya que tienden a ser co-regulados.
Hay varias maneras de evitar la sobre interpretación del grado de evidencia proporcionada por muchas variables correlacionadas. En primer lugar, una variable se puede definir de antemano como el resultado principal y, a continuación, solo se utiliza esta variable para probar la hipótesis o tomar una decisión. Un resultado primario se puede elegir en función de la literatura, después de experimentos pilotos o durante el desarrollo del ensayo experimental. Por ejemplo podría elegir el resultado con mayor sensibilidad para discriminar entre muestras de control negativo y de control positivo, o la variable con el coeficiente de variación (CV) más pequeño. A continuación, el resultado principal se utiliza para todos los experimentos posteriores porque se ha validado como la mejor variable. Los criterios a tener en cuenta al elegir un resultado primario necesitan aún mayor discusión. En este enfoque funciona bien la teoría, pero a menudo no en la práctica, porque si el resultado de la variable primaria no es significativo, pero una de las otras variables lo es, muchos investigadores encontrarían difícil seguir con el plan original y basar sus conclusiones en el resultado secundario, especialmente si se desea un resultado significativo. Un inconveniente en el enfoque de resultado primario es que las otras variables tienen cierta información adicional que sigue sin utilizarse. Parece derrochado e ineficiente que los datos se recopilen pero no se pongan en uso. Una forma en que se podrían utilizar los datos adicionales es reducir el error de medición. Por ejemplo, de fuerza, una persona puede tener un hombro rígido en el día de las pruebas, otra puede tener una rodilla dolorida y otra una mala espalda. Dependiendo de cuánto un ejercicio implica una parte del cuerpo lesionado, una sola medida puede subestimar la verdadera fuerza de una persona. Si las tres mediciones pudieran combinarse, entonces podría obtenerse una mejor estimación de la fuerza global.
Esto nos lleva al segundo método de tratar con muchas variables correlacionadas: combinarlas en un conjunto de menos variables que todavía se relacionan con la variable latente de interés. Podríamos, por ejemplo, añadir la cantidad levantada en los tres ejercicios para obtener una nueva variable llamada “peso total” que es la suma de cada tipo de medición de esfuerzo. El peso total es una combinación lineal de las tres variables originales y se puede utilizar como resultado principal en un análisis. Las variables medidas son todas del mismo tipo y tienen las mismas unidades (por ejemplo kilogramos) por lo que la suma simple que las combina es significativa. Cuando las variables observadas tienen unidades diferentes, sumarlas crea una variable que es difícil de interpretar. Otro problema con la adición de variables es que las variables con valores más grandes tendrán una mayor influencia en el total de las variables más pequeñas. Esto es indeseable y nos gustaría que todas las variables contribuyeran por igual al total. Es deseable un método general para combinar variables de diferentes tipos, donde cada variable hace la misma contribución. Afortunadamente, muchos métodos están disponibles y los dos más comunes son el análisis de componentes principales (PCA[19]) y el análisis de factores[20]. Relacionados con estos métodos están las mediciones compuestas, que son una combinación de varías variables medidas, pero pueden estar en diferentes escalas.
La suma de las subescalas da la puntuación general del efecto general. Aunque las puntuaciones compuestas tienen la ventaja de reducir el número de variables de resultado, se oscurecerán los diferentes patrones de las subescalas. La puntuación compuesta puede ser la misma, a pesar de las diferencias en su manifestación de la enfermedad. Por esta razón, las puntuaciones compuestas son especialmente problemáticas cuando se buscan asociaciones entre los resultados clínicos y la expresión genética o biomarcadores de imágen.
3.5.6 Sesgo de confirmación
El sesgo de confirmación es la tendencia a buscar, interpretar, enfocar, y recortar información que confirma una hipótesis de investigación y puede manifestarse de muchas maneras. Por ejemplo, supongamos que se lleva a cabo un estudio de microarray y se deriva una lista de genes expresados diferencialmente entre pacientes enfermos y controles saludables. Es común proporcionar apoyo a un gen en esta lista citando estudios previos encontraron una asociación entre el gen y la enfermedad en cuestión. Una búsqueda en PubMed llevada a cabo utilizando el nombre de la enfermedad más un gen de interés como términos de búsqueda. Los documentos encontrados tienden a ser aquellos que muestran un vínculo o asociación con el gen y la enfermedad y esto puede parecer proporcionar apoyo en evidencia firme para hallazgos del estudio de microarray. Pero, ¿cuán convincente es este enfoque? Ignorando por el momento la calidad y relevancia de los documentos encontrados, ¿Qué pasa con los estudios que examinaron el gen (o proteína) de esta enfermedad pero no lo encontraron relevante? Podría haber artículos que abordan la misma cuestión de investigación, pero solo aquellos que mencionan la enfermedad y el gen en el título o resumen aparecerán en la búsqueda PubMed, y tenderán a ser unos con resultados estadísticamente significativos. Los estudios en la búsqueda de literatura podrían ser principalmente aquellos con resultados positivos. Esto es especialmente cierto con los experimentos genómicos donde se examinan todo los genes, pero solo unos pocos se mencionarán en el título o resumen, y por lo tanto se encontrará con una búsqueda PubMed sesgada. Sugerimos realizar un búsqueda Omnibus (GEO) bases de datos, para encontrar el gen de interés en todos los estudios de microarray y NGS que mencionan la relación con la enfermedad, ahora se está en posibilidad de ver al gen que se expresa en diferentes pacientes y controles de salud.
El sesgo de confirmación también puede ocurrir durante el análisis y la interpretación de los datos. Supongamos que los datos son ligeramente sesgados y se toma la decisión de transformarlos. Se realiza un análisis tanto de los datos sin procesar como de los transformados, y si solo uno de estos análisis proporciona un resultado de interés, entonces ese resultado se informa. Es como si por definición el análisis correcto fuera el que da el resultado significativo; los otros análisis que se llevaron a cabo son ignorados porque no apoyan la hipótesis de la investigación.
Otra fuente de sesgo de confirmación se produce al decidir qué datos incluir en una publicación y que referencias citar para apoyar una discusión. Cuando los datos no se ajustan a la discusión en general, pueden excluirse. También existe la tendencia a matizar la importancia de los resultados negativos y a citarlos menos, especialmente en las ciencias biológicas[21]. El sesgo de confirmación es difícil de evitar, pero se pueden hacer esfuerzos para encontrar resultados negativos y asegurarse de que no se descuenten o citen incorrectamente, solo es necesario reformular nuestras preguntas para asegurar que nuestra visión es la correcta. Por ejemplo, además de preguntarnos ¿existe una asociación entre este gen y la enfermedad?, qué sesga a uno para encontrar evidencia de apoyo, también se pregunta ¿por qué no hay asociación entre el gen y la enfermedad?, qué centra la búsqueda en encontrar evidencia negativa.
3.5.7 Efectos de expectativa
Se producen cuando las expectativas de un científico influyen en las mediciones o evaluaciones. Por ejemplo, si espera que los ratones transgénicos presenten más de un comportamiento en comparación con los de tipo silvestre, las calificaciones subjetivas de comportamiento pueden sobrestimar su prevalencia en los ratones transgénicos. O bien, si no se esperan diferencias entre las camadas de animales o Lots de muestras procesadas por separado, la agrupación sutil de puntos de datos puede ignorarse o atribuirse al ruido aleatorio.
Un ejemplo clásico de efectos de expectativas es la historia de N-rays, una historia arraigada en un diseño experimental deficiente[22]. En 1903, el físico Rene Prosper Blondlot afirmó haber descubierto un nuevo tipo de radiación, que llamó N-rays, y muchos científicos respetados reprodujeron sus resultados. Fue un hallazgo importante y recibió mucha atención de la comunidad científica. Los rayos N-rays fueron supuestamente emitidos por objetos orgánicos, y biólogos y médicos se interesaron. N-rays se detectaron evaluando subjetivamente el brillo de una chispa o la oscuridad de las placas fotográficas. Los investigadores no fueron cegados durante estas evaluaciones y vieron lo que esperaban y querían ver: cuando hacemos X, la chispa se vuelve más brillante. Sin embargo, los efectos desaparecieron en experimentos posteriores cuando los investigadores no eran conscientes de la condición experimental al evaluar el brillo de la chispa, es decir, cuando fueron cegados.
Entre 1903 y 1906, unos 300 artículos sobre N-rays, fueron publicados por 100 científicos[23]. Un par de años más tarde a su descubrimiento, pocos creyeron en la existencia de N-rayos, y la ciencia parecía estar funcionando como debería: se hizo una afirmación, los científicos investigaron y finalmente se encontró la verdad. Por otro lado, si los efectos de expectativas se hubieran controlado desde el principio, 100 científicos no hubieran perdido su tiempo. La ceguera y la aleatorización podrían haber evitado los efectos de expectativa.
3.5.8 Sesgo de retrospectiva
El sesgo de retrospectiva es la tendencia a encontrar explicaciones para los resultados que no se predijeron, a menudo consistentes con la hipótesis o el paradigma prevaleciente. Es principalmente un problema para experimentos exploratorios (a diferencia de los experimentos confirmatorios), y se producen siempre que un efecto o asociación imprevista es estadísticamente significativa y llegamos a la conclusión que eso tiene sentido o lo sabíamos posible. A veces la explicación no es obvia, pero después de un poco de pensamiento y una búsqueda PubMed, uno puede apelar a alguna teoría o encontrar un par de papeles que puedan ser de apoyo a una explicación. Con casi 25 millones de entradas en PubMed, se puede encontrar algo útil. Además, dado el número de resultados falsos positivos en la literatura, no es difícil encontrar al menos un documento que respalde cualquier hallazgo dado. La única manera de validar estos resultados es admitir que no se encontrará en un nuevo experimento y luego llevar a cabo el nuevo experimento[24]. Cuando una explicación viene después del resultado, es extremadamente débil y poco convincente. Los investigadores pueden desarrollar diferentes explicaciones para los mismos resultados dependiendo de sus conocimientos de fondo y los documentos con que tropiezan en su búsqueda en la Web. La explicación propuesta puede ser cierta, pero la única manera de saberlo con seguridad es probarla en un experimento posterior.
El sesgo de retrospectiva se puede evitar haciendo una predicción antes de que se lleve a cabo el experimento. Ayuda anotar los resultados esperados del experimento; por ejemplo, que el grupo de tratado expresara el Gen X a un nivel superior. Uno podría ir un paso más allá y predecir el tamaño del efecto y su incertidumbre, como un aumento de 2 veces con un CI entre 1.5-2.5 veces. La estimación puede basarse en los tamaños de efectos comúnmente vistos y reportados en la literatura para experimentos o un estudio piloto. Tal vez escribir un valor para un efecto increíblemente grande. Esto ayuda a calibrar las predicciones y las intuiciones. Si el resultado es un aumento de 10 veces, entonces la reacción habitual de la excitación podría ser atemperada con preocupación de por qué la predicción está tan diferente y por qué el efecto es tan grande. ¿Hay otra fuente de variación que esté influyendo en los resultados? Además, si Gen X es el mismo entre grupos, pero Gen Y y Gen Z se expresan diferentemente, entonces no se puede afirmar que se esperaban estos resultados.
3.5.9 Efecto de pastoreo
El comportamiento de pastoreo es la tendencia a seguir a la multitud científica cuando se trata de una teoría creída y métodos utilizados (ya sea experimentales o estadísticos), la ciencia no es inmune a las tendencias de moda en las comunidades de conocimiento. Por ejemplo, cuando se cree que una proteína o un proceso biológico es de importancia para una enfermedad. Luego, todo el mundo pasa a estudiar otra proteína o proceso que ahora se cree que es de mayor importancia. En el descubrimiento de fármacos, muchas empresas persiguen a los mismos objetivos casi al mismo tiempo. Este comportamiento de pastoreo que hace que sea difícil publicar hallazgos que van en contra de la opinión predominante. Y cuando se publican tales resultados, pueden ser ignorados por la comunidad de investigación. Se argumenta que los hallazgos son ignorados cuando no contribuyen a la narrativa general que los científicos utilizan para entender e interpretar los resultados y citan estos autores su propio trabajo como ejemplo[25].
El efecto de pastoreo también puede ocurrir a nivel de un grupo de investigadores, donde todos los miembros tienen las mismas creencias, se entrenan en los mismos métodos y llevan a cabo experimentos para apoyar un único punto de vista. Esto puede conducir a la endogamia científica[26], donde las realizaciones no son realmente independientes porque tienen los mismos sesgos y errores que el experimento original[27].
El comportamiento de pastoreo es un problema porque puede haber pocas personas que tomen una visión crítica de una área de investigación, exijan que se revisen los supuestos y consideren seriamente explicaciones alternativas. Un riesgo es que se supriman los resultados contradictorios o negativos y se vuelvan a ejecutar los experimentos hasta que se obtenga la respuesta “correcta”. Este comportamiento es difícil de superar porque a menudo toman premisas básicas adoptadas de la moda, y luego tratan de extender el conocimiento científico con una dirección determinada. Es poco probable que la advertencia de ser un pensador independiente sea útil, ya que la mayoría de las personas, científicas o de otro tipo, ya creen que lo son como si fueran inmunes al sesgo.
Muchos artículos de investigación proporcionan información suficiente para evaluar si el diseño experimental y el análisis estadístico son apropiados o si los investigadores participaron en prácticas de investigación cuestionables, como la presentación de informes con solo resultados favorables. Ha habido una gran cantidad de introspección por parte de la comunidad de investigadores biomédicos últimamente con respecto al sesgo y la falta de reproducibilidad[28], lo que sugiere que hay problemas graves con la investigación biomédica actual. Estas discusiones han llevado a las principales revistas como Science y Nature a implementar estándares de informes más estrictos[29]. El Instituto Nacional de Ciencias (NIH) sugiere pilotear varios métodos para mejorar la reproducibilidad de la investigación, incluida la formación en diseño experimental para estudiantes universitarios[30].
Además, Science ha creado recientemente una Junta Estadística de Editores de Revisión, que revisará los manuscritos y recomendaciones para aquellos que deberían recibir una revisión más exhaustiva[31].
3.6 Lo que dicen los estadísticos
Los estadísticos están en una posición única porque ven los datos sin procesar e interactúan con los científicos antes de que se publiquen los artículos. A menudo se exponen a “la historia real” en lugar de la versión desinfectada que se publica. También están menos comprometidos en el resultado, lo que les permite ser más imparciales. Los bioestadísticos aplicados también trabajan con muchos grupos de investigadores con amplia exposición a la forma en que los biólogos llevan a cabo experimentos. Dado los conocimientos de los estadísticos sobre el diseño de experimentos y la realización de inferencias a partir de datos, tales comentarios deben hacer que uno se detenga y reflexione sobre la calidad de los experimentos en las ciencias biológicas. El comentario de Nelder: “Muchos estadísticos tienen sus propias historias de terror”, alude a la preocupación generalizada de los estadísticos. Cabe destacar que el comentario fue hecho por Ficher en 1938 y que Nelder 60 años después lo sugiere dentro de la calidad de los experimentos. Fisher hizo esta declaración en un congreso de estadística y Nelder dentro de una publicación de revista[32]. Todos los comentarios estaban dirigidos a otros estadísticos, que tal vez asintieron con la cabeza a sabiendas de las preocupaciones de los biólogos.
Algunos biólogos pueden sentirse ofendidos por los comentarios de los estadísticos, pero considere que los biólogos podrían decir si los estadísticos comenzaron un experimento de laboratorio sin tener en cuenta las buenas prácticas, como el uso de de controles experimentales y la validación de reactivos. El punto sigue siendo el diseño experimental y el análisis de datos como actividades básicas en la biología experimental, y muchos expertos en estas áreas del descubrimiento científico piensan que el nivel general de conocimiento entre los biólogos es insuficiente. Los biólogos no tienen la culpa, la educación en estás áreas es mínima en el pensamiento matemático y estadístico en lo particular, dado que se considera aburrido para la práctica científica. Que muchos biólogos no vean cómo las estadísticas y el diseño experimental son críticos para su actividad profesional de investigación es un fracaso de la comunidad universitaria. Los biólogos quieren hacer buena ciencia y aprenderían fácilmente algo si mejorará su desempeño profesional. La formalidad rígida de establecer una hipótesis nula (que se sabe que es falsa), compararla con una hipótesis alternativa (que no es interesante), calcular valores p que no dicen nada sobre la hipótesis e intervalos de confianza que no proporcionan confianza, es suficiente para convencer a muchos biólogos de que las estadísticas no tienen nada útil que ofrecer.
No es obvio cómo las estadísticas y el diseño experimental pueden mejorar el descubrimiento científico y es responsabilidad de los estadísticos hacer esta conexión para la formación científica de los universitarios[33]. Centrarse en el diseño experimental es una forma de hacer que las estadísticas sean más relevantes para los biólogos, el enfoque adoptado en este curso, se utilizan métodos bayesianos para la inferencia estadística en lugar de métodos frecuentados[34].
3.7 Lo que dicen al respecto los científicos
Los biólogos pueden despreciar lo que piensan los estadísticos, tal vez porque los estadísticos son percibidos como carentes de conocimiento biológico o están obsesionados pedantemente con asuntos triviales y se pierden en un panorama más amplio[35]. Las preocupaciones que los científicos tienen sobre sus propias áreas de investigación a menudo no se capturan en la literatura, sino que se conversan entre pasillos y conferencias, aunque ahora algunos resultados publicados en Cancer Cell[36], discuten esta relación necesaria para auditar científicamente los hallazgos publicados también en Nature[37]. La falta de reproducibilidad no es un fenómeno reciente, desde los años 1970 surge con fuerza, pero es interesante por qué la atención ha aumentado recientemente como exigencia más estrecha entre estadísticos y biólogos experimentales[38].
3.7.1 Evidencia empírica y prácticas de investigación cuestionables
Martinson y colegas solicitaron de manera anónima que 3247 científicos financiados reportaran sus prácticas de investigación cuestionables durante los últimos tres años[39]. En general, encontraron que el 33% de los científicos informaron haber incurrido en al menos uno de sus 10 faltas graves, el 0.3% de los encuestados admitió falsificar datos, el elemento más grave de la lista de Martinson; 6% admitió no presentar datos que contradicen sus resultados reportados, el 12.5% dijo que pasó por alto la interpretación errónea o cuestionable de los datos de otros, el 15.5% dijo que cambió el diseño experimental, los métodos o los resultados en respuesta a la presión de la fuente de financiamiento, el 13.5% admitió el uso de diseños de experimentación indagados o inapropiados y el 15% de las observaciones de los análisis basados fueron por una sensación intestinal de que eran inexactos. Un metanálisis de 18 estudios de Fanelli encontró que el 2% de los científicos admitieron fabricar, falsificar o modificar datos o resultados al menos una vez, y el 34% admitió otras formas de malas prácticas[40], cuando preguntó sobre la idea de que otros colegas que revisaron su literatura, 72% consideró algún tipo de mala práctica en especial la falsificación de datos.
Participar en algunos de los comportamientos anteriores no solo implica una conducta deshonesta, o intento de engañar. Puede haber razones éticamente justificadas para darnos cuenta que una mala o nula formación estadística rigurosa y diseño experimental real conduce a los sujetos especialmente a distorsionar sus valores científicos de investigación.
3.8 Calidad de los estudios
Una cuestión separada a las prácticas cuestionables de investigación es la calidad de los estudios. Un objetivo de todos los experimentos es obtener estimaciones imparciales de los tamaños de los efectos y una precisión adecuada de esas estimaciones. Estos resultados se utilizan para apoyar o refutar una teoría o hipótesis, planificar más experimentos, tomar decisiones de tratamiento para los pacientes o probar un nuevo medicamento, ninguno de los cuales se puede hacer bien con estimaciones sesgadas o precisión defectuosa. Hay dos áreas principales donde los recién llegados a la investigación fallan. La primera está en el diseño y ejecución del experimento, y la segunda en el análisis y la interpretación.
Dos problemas principales identificados en el diseño y la ejecución son la falta de aleatorización y falta de ceguera[41], que se determina a partir de los manuscritos. Algunos estudios pueden haber sido aleatorizados y cegados, pero los autores no lo informaron. Sin embargo, los estudios que no mencionan el uso de aleatorización o ceguera tienen tamaños de efectos más grandes en comparación con los estudios que informaron utilizar estas técnicas de acuerdo con Dirnagl[42]. Esto es consistente con las malas prácticas experimentales que conducen a resultados inflados. Generalmente se examina el uso correcto de pruebas estadísticas, si los datos se han eliminado sin mención o un desajuste entre las estadísticas de prueba, los valores p, y las conclusiones[43].
Otro problema importante es la pseudorreplicación, una inflación artificial del tamaño de la muestra[44], tales errores son comunes. Un tema importante para los experimentos in vivo son los efectos de variación de litter-to-litter en las variables de resultado[45]. Esta es una fuente grande y poco apreciada de variabilidad que puede aumentar falsos positivos y negativos. Los manuscritos rara vez discuten cómo se tuvieron en cuenta los efectos de datos de basura o litter. Como ejemplo, recurramos a un estudio de caso, esta vez uno que involucra el superóxido dismutasa (SOD1) en un modelo de ratón transgénico con esclerosis lateral amiotrófica. Los estudios preclínicos que utilizan este modelo biológico, han mostrado suficiente eficacia para varios fármacos diferentes para proceder a los ensayos clínicos[46]. En un meta-análisis de la literatura clínica, se mostró que solo el 31% de los estudios reportaron la asignación aleatoria de animales a condiciones de tratamiento e incluso menos realizaron evaluación ciega de resultados[47]. Y en estudios inéditos muestran que no confirmaron los hallazgos iniciales (Schnabel J. 2007). Un estudio de gran escala y debidamente realizado por Scott y colegas, descubrió fuentes de variabilidad que podrían explicar los falsos positivos en la literatura, como efectos litter[48].
Cuando se trata de análisis e informes, se produjo una incongruencia entre las estadísticas de prueba y los valores p en el 11% de los artículos publicados en 2001 en Nature y en el British Medical Journal[49], esto se considera que se debe a errores de redondeo, tipográficos o de copiar y pegar, o quizás errores en el análisis. El 15% de los documentos analizados tenían al menos un error que condujo a un cambio de conclusión, definido como un valor p cambiado a ambos lados de 0.05 después del cálculo. Además, señalaron que estos errores tendían hacia resultados significativos. Se puede concluir que se trata de intentos de engaño, ya que un valor p no significativo puede ser revisado y examinado, por lo tanto, corregido, mientras que un valor p significativo suele calificarse de incuestionable. Estos errores podrían explicar la prevalencia peculiar de valores p justo por debajo de 0.05[50]. Otro estudio encontró que la renuencia a compartir datos estaba asociada con una mayor prevalencia de errores de notificación y que la falta de voluntad para compartir datos era mayor cuando los errores influyeron en la significación estadística[51].
Muchos de los errores anteriores son probablemente malos hábitos y atribuidos a un descuido, y aunque disminuyen la calidad general de los resultados publicados son difíciles de eliminar por completo. Más preocupante es cuando se utilizan procedimientos inferenciales incorrectos. Por ejemplo, supongamos que un científico quiere mostrar que un compuesto tiene un efecto solo en ratones normales, pero no en ratones que tienen un gen objetivo bloqueado. El método adecuado para abordar esta pregunta es probar el fármaco por el efecto de interacción del genotipo, pero la mitad de los artículos de neurociencia en las revistas de Science y Nature no analizan estos datos correctamente[52]. En su lugar muchos investigadores tratan de apoyar su hipótesis demostrando que la diferencia entre el fármaco y el grupo de control es significativo en los ratones de tipo salvaje (p<0.05), pero no en los ratones con el gen bloqueado (p>0.05). Aunque hay cierta lógica en esto, es un análisis incorrecto porque la diferencia entre significativo y no significativo no es estadísticamente significativa[53]. Cuando algunos efectos fueron grandes, es poco probable que las conclusiones cambiaran si se considerarán otros métodos apropiados. Para otros, es posible que sea necesario revisar las conclusiones.
3.8.1 Reproducibilidad de los estudios
La pregunta es si las prácticas cuestionables y una mala calidad del estudio afectan las conclusiones generales, y por lo tanto, el conjunto de conocimientos científicos. Tal vez no todos los resultados examinados se informan en los documentos, los puntos de datos inusuales se eliminan rutinariamente y los métodos analíticos incorrectos son comunes, pero, ¿es probable que se llegue a la conclusión correcta la mayor parte los casos? Parece que la respuesta es no. Un grupo de científicos confirmaron que los resultados de solo 6 de 53 (11%) de los informes emblemáticos y alrededor de un tercio de los estudios (14 de 67) podrían reproducirse[54]. Estos informes fueron evaluados por la industria farmacéutica y biotecnológica, estas invierten una gran cantidad de esfuerzo para reproducir los resultados y reunir más evidencias para validar la conexión, de lo contrario cualquier inversión adicional en consecuencia sería una pérdida de tiempo y dinero. Estos esfuerzos de replicación por parte de la industria son un serio intento de establecer efectos reales.
3.8.2 Publicaciones sesgadas
El sesgo de publicación ocurre cuando ciertos tipos de resultados tienen mayor probabilidad de ser reportados que otros. Los resultados reportados tienden a ser aquellos que son estadísticamente significativos (p<0.05) y apoyan la hipótesis de investigación. Por lo tanto, la existencia y magnitud de los efectos será sesgada si es más probable que se publiquen resultados positivos que los resultados negativos. El sesgo de publicación puede surgir si no se presentan experimentos completos, o si solo se concluyen determinados resultados de un experimento en la publicación final, mientras que otros se han omitido. También podría surgir si los editores tienden a rechazar documentos con resultados no significativos. ¿Cómo sabemos que existe sesgo de publicación? A menudo se estima en revisiones sistemáticas de literatura relevante y pertinente en un metaanálisis. Las revisiones sistemáticas permiten tener una visión panorámica de las prácticas, métodos y sesgos presentes en los informes de investigación. En este método se comparan los números p significativos notificados y su relación con los tamaños de efectos potenciales; ocasionalmente se conoce un número de estudios recientes, lo que permite comparar si los resultados fueron notificados con calidad en la naturaleza de metodología estadística.
3.9 La cultura científica no conduce a la “búsqueda de la verdad”
La ciencia académica ha sido descrita como un mercado de torneos de esgrima de las ideas, se caracteriza por una intensa competencia donde justos en comunidades de conocimiento, tenemos disputas permanentes, consensos y productividad solidaria pública a través de mecanismos de informes y otras literaturas. Las publicaciones son las unidades principales de medición de resultados por los cuales somos juzgados y recompensados. Los biólogos experimentales están dentro de un contexto de valor en el factor de impacto de las revistas en que hacen sus informes públicos; si uno es primer o segundo autor, pero esto es difícil debido al número limitado de artículos aceptados por las principales revistas. Las publicaciones son necesarias no solo para las recompensas, sino para sobrevivir en la ciencia. No es sorprendente que los científicos traten de maximizar la producción de publicaciones, lo que puede requerir elevar su calidad de investigación y en ocasiones caen en el fraude en casos extremos, de recaer conscientes en malas prácticas de investigación.
Las estructuras de incentivos y presiones para publicar difieren entre la investigación industrial y la académica. El sesgo de publicación se hace más evidente en los estudios patrocinados por la industria[55]. Las razones de estos hallazgos no están claros, pero merecen su atención en este sector.
La probabilidad de que un resultado sea verdadero depende en parte de la probabilidad de que sea cierto antes de que se lleve a cabo el experimento, conocido como probabilidad previa[56]. Por ejemplo, supongamos que un investigador desea analizar si la radiación del teléfono móvil afecta la expresión génica en el cerebro de los ratones. Asigna aleatoriamente un grupo de ratones para que que estén expuestos a la radicación y tiene un grupo de control que no está expuesto. Luego analiza la expresión de cinco genes que cree, basado en investigaciones previas y conocimiento biológico, en el cerebro son relevantes para la radiación electromagnética de teléfonos móviles. Si se encuentra un efecto en uno o más de los genes, los resultados tendrán una probabilidad relativamente alta ser verdad porque los genes fueron seleccionados específicamente porque se creía que eran relevantes o sensibles a esta intervención experimental.
Una tendencia en las ciencias biológicas experimentales es la capacidad de medir cada vez más resultados de forma rápida y económica. Esto incluye todas las tecnologías genéticas, el análisis de Imag4 de alto contenido y el registro automatizado de muchos parámetros de comportamiento en estudios con modelos animales. A medida que se hace más fácil medir parámetros, la probabilidad previa de cualquier resultado en particular disminuyó. Es probable que el número de pruebas del número de falsos positivos aumente con el tiempo, y hay pruebas de que el número de resultados significativos está aumentando[57]. A menos que los científicos mejoren en predecir o verificar sus hipótesis, no se reducirán los falsos positivos. Los ensayos clínicos a menudo en fase III tienen éxito poco más de lo usual[58]. Tales ensayos experimentales tienen una mayor probabilidad de éxito porque se basan en ensayos anteriores de fase I y II, con más años de investigación preclínica. Al acumular poder estadístico de experiencia esto mejora el diseño experimental y su análisis.
Como se mencionó anteriormente, el sesgo se puede introducir de muchas maneras. Algunos son especialmente importantes en la experimentación biológica y están relacionados con el diseño y análisis de experimentos. El primero es el tratamiento de estudios exploratorios o de aprendizaje como estudios confirmatorios. El propósito de un estudio confirmatorio es probar algunas hipótesis específicas bajo un conjunto estrecho de condiciones. El ejemplo clásico de la fase III, que tiene una variable de resultados principal predefinida, una o muy pocas comparaciones de interés, una población específica de pacientes y un conjunto de condiciones definidas estrechamente en las que se llevará a cabo el experimento. Un estudio de aprendizaje o exploratorio, por otro lado, se trata de obtener la mayor cantidad de información posible sobre un sistema experimental y biológico (las condiciones bajo las cuales los efectos están presentes, cómo los individuos difieren en su respuesta, qué variable de resultado es la más sensible, y así sucesivamente.
El problema es que muchos experimentos biológicos tienden a ser experimentos de aprendizaje, pero luego se presentan como experimentos confirmatorios. Los efectos significativos se escriben como si se predijeran de antemano y los investigadores pueden convencerse fácilmente de que lo sabíamos todo el tiempo antes de obtenerlos. Cualesquiera que sean los resultados, se pueden hacer encajar una teoría o para apoyar alguna hipótesis. Esto se ha llamado Hypothesising después de que se conocen los resultados[59].
Una segunda fuente de sesgo relevante para el investigador experimental biólogo es el grado de libertad de los investigadores, que es la flexibilidad que tienen los científicos para seleccionar variables de resultado, para presentar, eliminar datos problemáticos, transformar variables, ajustar/normalizar/corregir variables, la elección del modelo o prueba estadística, si se utilizará una prueba de una o dos formas, y si se va a recopilar más datos[60]. Esto puede llevar a probar muchas opciones hasta que se obtenga la respuesta correcta y luego se presente como el único análisis de una hipótesis a priori. Un tercer problema que afecta el análisis de muchos experimentos biológicos es la confusión entre unidades experimentales y unidades de observación. La unidad experimental es la entidad, unidad o pieza de material experimental más pequeña que se puede asignar aleatoriamente e independientemente a diferentes condiciones de tratamiento[61] para aumentar el tamaño de muestra o si es necesario aumentar el número de unidades experimentales. Las unidades de observación, por otro lado, son las unidades en las que las mediciones se hacen y pueden o no corresponder con las unidades experimentales.
Una cuarta cuestión es cuando el efecto de interés es difícil o imposible de estimar porque está mezclado o confundido con otros efectos biológicos o técnicos. Como ejemplo, considere el experimento de presión arterial con cinco personas en condiciones de tratamiento son hombres y los cinco en la condición placebo con mujeres. Se dice que el efecto del tratamiento está completamente confundido con el efecto del sexo y no se puede estimar. A menos que se asuma que no hay diferencia entre los sexos, el experimento sería un fracaso. La confusión parcial ocurre si hay un desequilibrio en la reacción de sexo entre los grupos de tratamiento, lo que también puede plantear problemas diferenciales. La confusión también puede ocurrir entre los efectos de tratamiento y los efectos técnicos, eso hace casi imposible diagnosticar a partir de la lectura de un manuscrito. Por lo tanto, es una fuente de sesgo poco apreciada. Tal confusión es la raíz de muchas historias de muertes por experimentación. Por lo general es posible evitar o minimizar la confusión mediante un experimento adecuadamente diseñado.
Una fuente común final de sesgo son modelos estadísticos inadecuados. Estos incluyen el tratamiento inapropiado de los datos como distribuciones normales, cuando se ignora la censura sin incluir variables explicativas importantes en el modelo como cuestiones relevantes y no tener en cuenta las dependencias de los datos. En conjunto las preocupaciones metodológicas, los factores culturales y las prácticas de publicación distorsionan el registro científico de tal manera que gran parte de la literatura publicada tiene un valor cuestionable[62]. Y hacer más experimentos no necesariamente nos permitirá eliminar afirmaciones falsas y convergentes a la verdad[63]. A esto podemos añadir sesgo de citas, que ocurre cuando los resultados que apoyan las hipótesis del autor son más propensos a ser citados o citas a documentos que no respaldan la reclamación declarada en las proposiciones[64]. Los científicos difieren en cuanto a cuántos son los resultados publicados para asumir una situación consolidada; algunos son escépticos hasta que otros documentos apoyan los hallazgos iniciales, mientras otros asumen la correlación de los resultados hasta que surjan pruebas contradictorias, especialmente si el primer resultado fue publicado en revistas prestigiosas. El propósito de la discusión anterior no fue menospreciar a la ciencia o a los científicos, sino crear conciencia sobre los mecanismos de control de las comunidades de conocimiento para hacerse de conocimiento de credibilidad en el registro público de revistas. También fue para llamar la atención sobre el papel centrar del diseño experimental y la inferencia estadística, ambos en la generación de conocimiento científico de frontera.
3.10 Inferencia estadística frecuentada
Hay varios paradigmas o escuelas de inferencia estadística, los biólogos utilizan principalmente métodos frecuentadores. El método frecuentado fue desarrollado en gran medida por Sir Ronald Fisher, quien introdujo el concepto de una hipótesis nula y valores p como evidencia contra lo nulo. Así como Jerzy Neyman y Egon Pearson que introducen las hipótesis alternativas para rechazar o no la hipótesis nula basada en un nivel de significancia especificado previamente. Fisher tenía diferentes puntos de vista sobre la inferencia estadística por métodos frecuentadores, la única diferencia es dónde se pone el énfasis; las matemáticas son idénticas.
Pruebas de significación de hipótesis nulas (por su siglas en inglés NHST). Esta es la prueba más común de inferencia frecuentadora. El enfoque se centra en calcular un valor p y luego decidir si rechaza la hipótesis nula, que denotaremos como Ho, basada en un corte especificado previamente, como un valor p por debajo de 0.05. Dado el valor central de los valores p que se tienen en este método de inferencia, de una importancia sustantiva que le otorgan muchos científicos, uno esperaría que los científicos conocieran la definición de un valor p y la información que proporciona.
En primer lugar un valor p es la probabilidad de los datos. Un valor p es una probabilidad condicional, lo que significa que es la probabilidad de algo, dado que algo más es cierto. Específicamente, la hipótesis nula se da o se asume para ser verdad. Mientras que un valor p es la probabilidad de los datos, o datos más extremos, dado que la hipótesis nula es verdadera. Se puede escribir p: datos observados o datos más extremos | Ho=verdadera. La “|” se lee como “dado” y lo anterior se abrevia generalmente como P(Dato|Ho). Para aclarar esta definición vamos a utilizar un ejemplo de lanzamiento de monedas. Supongamos que tenemos una moneda y estamos interesados en hacer una inferencia sobre el sesgo de la moneda. Es decir, estamos interesados en probar si se trata de una moneda justa, definimos como tener la misma posibilidad de caras o cruz en sus lanzamientos. Definiremos el sesgo de la moneda como la propensión a caer cara y denotaremos esta cantidad con la letra griega 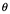 . Si la moneda es justa entonces
. Si la moneda es justa entonces 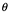 =0.5; caerá cara hasta el 50% de las veces en promedio. ¿Cómo podemos probar si una moneda es justa? Podríamos darle la vuelta muchas veces y contar las veces que cae cara. Supongamos que lanzamos la moneda 20 veces y aterriza caras en 15 de estos lanzamientos. Esperábamos 10 caras de 20 lanzamientos si era una moneda justa, pero observamos 15. La pregunta que tenemos ante nosotros es ¿Son las 15 caras observadas lo suficientemente lejos de 10 caras esperadas para concluir que la moneda no es justa? Alternativamente, podríamos preguntar si el sesgo observado de la moneda 15/20=0.75 está muy lejos del valor esperado de 10/20=0.5. Pero, ¿cómo definiríamos “lo suficientemente lejos” entre lo que esperamos y lo que observamos? La solución frecuentadora es utilizar una distribución de referencia basada en todos los resultados posibles del lanzamiento de una moneda justa 20 veces, junto con las probabilidades de esos resultados. A continuación, comparamos nuestro resultado observado con esta distribución para ver si es inusual. ¿De dónde proviene esta distribución de referencia? Es una distribución teórica, pero supongamos por el momento que no sabemos nada sobre distribuciones de estadísticas teóricas. Podríamos generar una distribución de referencia tomando una moneda que se sabe que es justa
=0.5; caerá cara hasta el 50% de las veces en promedio. ¿Cómo podemos probar si una moneda es justa? Podríamos darle la vuelta muchas veces y contar las veces que cae cara. Supongamos que lanzamos la moneda 20 veces y aterriza caras en 15 de estos lanzamientos. Esperábamos 10 caras de 20 lanzamientos si era una moneda justa, pero observamos 15. La pregunta que tenemos ante nosotros es ¿Son las 15 caras observadas lo suficientemente lejos de 10 caras esperadas para concluir que la moneda no es justa? Alternativamente, podríamos preguntar si el sesgo observado de la moneda 15/20=0.75 está muy lejos del valor esperado de 10/20=0.5. Pero, ¿cómo definiríamos “lo suficientemente lejos” entre lo que esperamos y lo que observamos? La solución frecuentadora es utilizar una distribución de referencia basada en todos los resultados posibles del lanzamiento de una moneda justa 20 veces, junto con las probabilidades de esos resultados. A continuación, comparamos nuestro resultado observado con esta distribución para ver si es inusual. ¿De dónde proviene esta distribución de referencia? Es una distribución teórica, pero supongamos por el momento que no sabemos nada sobre distribuciones de estadísticas teóricas. Podríamos generar una distribución de referencia tomando una moneda que se sabe que es justa 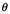 =0.5, la lanzamos 20 veces y contamos el número de caras. Si este procedimiento se repite 1 millón de veces obtenemos la distribución de referencia y nos diría cómo es probable que una moneda justa se comporte.
=0.5, la lanzamos 20 veces y contamos el número de caras. Si este procedimiento se repite 1 millón de veces obtenemos la distribución de referencia y nos diría cómo es probable que una moneda justa se comporte.
 21.53.52.png)
Figura 3.3 Distribución de referencia
La altura de las barras es la probabilidad de obtener ese número de caras y la suma de las alturas de todas las barras es igual a uno. Veríamos que la obtención de 10 caras de 20 lanzamientos es el resultado más común y si obtenemos 15 caras es mucho menos común. Los datos observados no se utilizan para generar la distribución de referencia. Tomaría mucho tiempo generar una distribución de este tipo mediante lanzamientos de una moneda justa repetidamente y aquí es donde las distribuciones teóricas hacen la vida más fácil.
Si una moneda justa cayera con 15 veces caras el 1.48% del tiempo, se puede calcular con la altura de la barra en x=15, y luego se multiplica por 100 para convertir la probabilidad en un porcentaje. Dado que este valor es pequeño, podríamos inferir que nuestra moneda es injusta porque 15 caras es inusual para una moneda justa. El problema con este enfoque es que la probabilidad de obtener cualquier resultado específico es baja. Por ejemplo, 10 caras en 20 lanzamientos ocurre el 17.61% del tiempo con una manera justa (con z=10 en la altura del gráfico). En otras palabras, el resultado esperado o más probable no ocurre con tanta frecuencia. Esto ocurre porque hay 21 resultados posibles (0,1,2,…,20 caras) y la probabilidad total se distribuye sobre estas posibilidades. La situación empeora si hay un mayor número de resultados posibles, sigamos, con 50 lanzamientos en lugar de 20. La solución utilizada por los estadísticos frecuentadores es calcular la probabilidad no solo del resultado observado, sino también de los resultados más extremos (16,17,18,19 y 20 caras), lo que nos devuelve a la definición de un valor p: es la probabilidad de los datos observados o datos más extremos, dado que la hipótesis nula es verdadera. En nuestro ejemplo los datos 15 caras y 20 lanzamientos, y los datos extremos son 16 a 20 caras, que trata de la primera parte de la definición y p=0.021; Lo “dado que la hipótesis es cierta”, esta parte refiere a cómo generamos la distribución de referencia. Recuerde que estamos interesados en probar si la moneda es justa, por lo que la hipótesis nula es que la moneda es justa (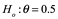 ) y por lo tanto generamos la distribución de referencia mediante el lanzamiento de una moneda que se sabe que es justa
) y por lo tanto generamos la distribución de referencia mediante el lanzamiento de una moneda que se sabe que es justa en un millón de veces.
La lógica de la referencia de frecuentar es enumerar primero todo los resultados posibles, junto con sus probabilidades, para generar una distribución de referencia basada en una hipótesis nula fijada por el investigador. Esta distribución se utiliza entonces para calcular la probabilidad de los resultados observados o cualquier cosa más extrema, que mencionamos anteriormente se puede escribir como 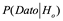 . Si esta probabilidad es baja, entonces uno puede concluir que
. Si esta probabilidad es baja, entonces uno puede concluir que  es cierta y se ha producido un resultado poco probable, o que es falsa
es cierta y se ha producido un resultado poco probable, o que es falsa  , pero no sabemos qué opción es correcta. Debido a que los resultados poco probables son poco probables, nosotros estamos favor de la segunda opción. La lógica se puede desglosar de la siguiente manera:
, pero no sabemos qué opción es correcta. Debido a que los resultados poco probables son poco probables, nosotros estamos favor de la segunda opción. La lógica se puede desglosar de la siguiente manera:
1. Si la moneda es justa, entonces 15 caras o más es poco probable.
2. Observamos 15 caras.
3. Por lo tanto, la moneda no es justa o la moneda es justa y ocurrió un evento improbable.
Este procedimiento ha causado malestar a algunos, porque una hipótesis se trata como fija y la probabilidad de los datos se calcula  . Sin embargo, una vez que se lleva a cabo un experimento, los datos son fijos, y un científico quiere hacer una declaración probabilística sobre una hipótesis
. Sin embargo, una vez que se lleva a cabo un experimento, los datos son fijos, y un científico quiere hacer una declaración probabilística sobre una hipótesis  . Las dos probabilidades pueden ser muy diferentes. Considere la probabilidad de que una persona con lupus tome algo y le salga salpullido
. Las dos probabilidades pueden ser muy diferentes. Considere la probabilidad de que una persona con lupus tome algo y le salga salpullido 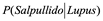 frente a la probabilidad de que una persona con erupción cutánea tenga lupus
frente a la probabilidad de que una persona con erupción cutánea tenga lupus 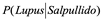 . La primera probabilidad es muy alta porque una erupción cutánea es un síntoma de lupus y la segunda probabilidad es baja porque hay muchas razones por las que alguien podría tener una erupción cutánea que no sea por lupus. Esta inversión entre lo que le dice un valor p y lo que desea saber es la razón principal de la interpretación errónea de los valores p, y también probablemente por qué los métodos frecuentados son difíciles de enseñar y entender por parte de los estudiantes.
. La primera probabilidad es muy alta porque una erupción cutánea es un síntoma de lupus y la segunda probabilidad es baja porque hay muchas razones por las que alguien podría tener una erupción cutánea que no sea por lupus. Esta inversión entre lo que le dice un valor p y lo que desea saber es la razón principal de la interpretación errónea de los valores p, y también probablemente por qué los métodos frecuentados son difíciles de enseñar y entender por parte de los estudiantes.
También se deduce que es en este enfoque el uso de la distribución de referencia pertinente y adecuada es fundamental para hacer inferencias correctas. En nuestro ejemplo hemos lanzado 20 veces y contado el número de caras. Por lo tanto, la distribución de referencia se basó en muchos lanzamientos hipotéticos de N=20. Supongamos que hacemos otro procedimiento de donde seguimos lanzando la moneda hasta que obtenemos 15 caras. Los datos son los mismos, 15 caras y 20 lanzamientos, pero el método de generación de los datos difiere. El primer caso, el número de lanzamientos se fija mientras que en el segundo caso se fija el número de caras. Los datos son idénticos, pero no distribución de referencia y, por lo tanto, los valore p difieren, dependiendo del método que se utilice. Si usamos un método para bifurcación y la distribución de referencia del otro método, los valores p serán incorrectos. La diferencia depende del espacio de muestra, que es el espacio de todos los resultados posibles. Si se fija el número total de lanzamientos, los resultados posibles son de 0 a 20 caras. Si el número de caras de fija, entonces el número mínimo de lanzamientos es 15, sin límite superior. Por lo tanto, el cálculo de un valor p depende del espacio de posibilidades.
Los métodos frecuentados y el enfoque de pruebas de significación de hipótesis nula tienen muchos aspectos críticos, una breve lista de ellos son[65]:
-Los valores p no identifican a los científicos lo que desean; proporcionan la probabilidad de los datos dados  , y los científicos desean la probabilidad de
, y los científicos desean la probabilidad de  o
o 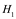 dados los datos. De hecho, ni siquiera es significativo hablar de la probabilidad de una hipótesis en la inferencia frecuentista.
dados los datos. De hecho, ni siquiera es significativo hablar de la probabilidad de una hipótesis en la inferencia frecuentista.
-El cálculo de un valor p se basa en datos no observados, es decir, en datos que podrían haberse producido pero no lo hicieron. Esto parece extraño, y hay evidencia de que esta no es una forma natural de pensar[66].
-La hipótesis nula exactamente “no afecta”, sin diferencia o ninguna asociación es a menudo falsa. Por ejemplo, muchos procesos biológicos tendrán alguna asociación distinta de cero y las diferencias entre sexos o camadas en muchas variables rara vez son exactamente cero. ¿Qué nos dice el valor p a partir de una distribución de referencia basada en una premisa falsa?
-Es difícil apoyar una hipótesis nula. Uno rechaza o no rechaza; al igual que un caso criminal, una persona es declarada culpable o inocente, pero no ambas. A menudo, el interés es concluir que dos grupos son los mismos, o al menos lo suficientemente similares para fines prácticos y, la aplicación de métodos frecuentadores no es sencilla.
-Los valores p son ampliamente incomprendidos, incluso por algunos estadísticos[67].
-Fomenta el pensamiento dicotóctono, un resultado es significativo o no lo es, y por lo tanto automatiza el razonamiento y puede conducir a un acantilado psicológico en muchos casos[68].
-Un valor p pequeño podría reflejar un tamaño de muestra grande o datos precisos en lugar de una diferencia significativa entre grupos.
-Conduce a sesgo de publicación porque es más probable que se publiquen resultados significativos 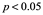 .
.
-La posibilidad de falsos positivos es constante (normalmente establecida en 0.05) independientemente del tamaño de muestra. Esto también es contra-intuitivo; a medida que aumenta el tamaño de muestra, seguramente uno debe ser capaz de llegar a la conclusión correcta.
-Los valores p dependen de las intenciones (a menudo no declaradas) del científico. Por ejemplo, cuándo dejar de recopilar datos (después de 20 lanzamientos, después de 15 caras o después de 1 minuto de lanzamientos). O si uno está interesado en detectar las salidas del calor nulo en una o dos direcciones.
Las críticas a los métodos frecuentados han aumentado en los últimos años y pocos argumentan que son muy adecuados para el descubrimiento científico[69], o al menos reconocer que el enfoque tiene algunas características positivas[70]. Sin embargo, este se ha convertido en el paradigma dominante utilizado por los científicos para analizar datos.
3.10.1 Estimación de parámetros
Un segundo enfoque para la inferencia frecuentada es la estimación de parámetros. Aquí, el enfoque no se centra en probar la hipótesis y obtener un valor p, sino en obtener una estimación del tamaño de un efecto (el parámetro) y la incertidumbre en esa estimación. En un experimento comparativo, la estimación se denomina tamaño de efecto y podría ser la diferencia entre los medios del grupo de control y el grupo tratado, junto con un intervalo de confianza del 95%. En muchos experimentos estimar el tamaño de efecto es más importante que probar una hipótesis. A menudo se conoce de antemano que habrá algún efecto y rechazar una hipótesis nula es poco interesante y poco informativa. Algunos han sugerido que centrarse en las estimaciones de parámetros puede superar algunos de los problemas con NHST, especialmente en el enfoque en valores p y el pensamiento dicotóctono[71]. Pero la diferencia todavía se basa en una distribución de referencia y los intervalos de confianza también tienen una interpretación de frecuencia. Al igual que los valores p, los intervalos de confianza a menudo son malinterpretados por los investigadores[72].
Al igual que un valor p, un intervalo de confianza no nos dice la probabilidad de una hipótesis o valor de parámetro, pero a menudo se malinterpreta de tal manera. La opción sobre la creencia de la verdadera diferencia media y, ya que los métodos frecuentados gobiernan las probabilidades subjetivas, esta opción es incorrecta. Puesto que la confianza es un estado mental, un intervalo de confianza sugiere que podemos estar 95% seguros de que el valor verdadero de la estimación está entre los límites superior e inferior. Al igual que el término significación, el significado común de la confianza interfiere con la definición estadística. Para cualquier experimento dado, el valor verdadero está dentro o fuera del CI del 95%, por lo que la probabilidad es cero o uno. La verdadera diferencia media es o no está entre estos valores. Si el experimento se lleva a cabo una segunda vez, los valores CI superiores e inferiores serán diferentes y de nuevo, el valor verdadero está o no está contenido dentro de este CI. Un 95% en CI le dice que si el experimento se repite muchas veces, esperamos que el 95% de las veces los intervalos contendrán el valor verdadero del parámetro.
Esto, una vez más, no es lo que se desea para la inferencia científica, pero es difícil no pensar y hablar de los CI como que representan un rango de intervalos que son de alguna manera más creíbles que los valores fuera del intervalo. El único consuelo es que un análisis bayesiano (que puede hacer declaraciones sobre la confianza de ciertos valores sobre otros) a menudo corresponden a los CI frecuentados, por lo que una interpretación incorrecta puede coincidir con la correcta. More y colegas ofrecen un excelente debate sobre la interpretación de los intervalos de confianza y cómo se relacionan con los intervalos creíbles bayecianos[73].
Trazar estimaciones e intervalos de confianza es una buena manera de resumir los resultados de un experimento. Los resultados para el lanzamiento de una moneda, por ejemplo, la línea de referencia horizontal están en 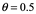 ; que era la hipótesis nula de que la moneda es justa. Dado que el CI inferior del 95% no cruza (aunque está cerca) se rechaza la hipótesis nula, pero el verdadero sesgo de la moneda es incierto porque los CI del 95% son amplios. El gráfico del respectivo ejemplo, nos dice lo que ya sabemos, que no es un valor plausible para el sesgo de esta moneda, pero también tenemos una impresión de la precisión de la estimación. Estos gráficos son más útiles cuando comparan muchos efectos en varios experimentos. Es fácil notar efectos triviales pequeños que tienen valores p pequeños (debido a un gran tamaño de muestra) y efectos que pueden no ser estadísticamente significativos, pero son grandes biológicamente o clínicamente significativos. En este último caso, esto podría incitar a recopilar más datos para reducir la incertidumbre en la estimación.
; que era la hipótesis nula de que la moneda es justa. Dado que el CI inferior del 95% no cruza (aunque está cerca) se rechaza la hipótesis nula, pero el verdadero sesgo de la moneda es incierto porque los CI del 95% son amplios. El gráfico del respectivo ejemplo, nos dice lo que ya sabemos, que no es un valor plausible para el sesgo de esta moneda, pero también tenemos una impresión de la precisión de la estimación. Estos gráficos son más útiles cuando comparan muchos efectos en varios experimentos. Es fácil notar efectos triviales pequeños que tienen valores p pequeños (debido a un gran tamaño de muestra) y efectos que pueden no ser estadísticamente significativos, pero son grandes biológicamente o clínicamente significativos. En este último caso, esto podría incitar a recopilar más datos para reducir la incertidumbre en la estimación.
En resumen en este apartado, se hizo hincapié en las limitaciones del enfoque frecuentado de la inferencia, en parte porque las limitaciones son la razón por la que muchos científicos malinterpretan los valores p y los intervalos de confianza. Los métodos bayesianos son conceptualmente más simples, pero no se discuten porque tanto los métodos frecuentados como los bayesianos conducirán a conclusiones similares en experimentos con pocos parámetros, poca información previa y un tamaño de muestra razonable[74].
Ahora es necesario introducirnos al software disponible R, para aprovechar su potencial estadístico de código abierto utilizando popularmente un lenguaje interpretado. Es necesario darse el tiempo para aprenderlo.
Referencias
[1] Butts, Robert. (2008). William Whewell: Philosopher of Science, and: William Whewell: A Composite Portrait (review). Journal of the History of Philosophy. 30. 621-623. 10.1353/hph.1992.0088.
[2] Charles Darwin, The Descent of Man, and Selection in Relation to Sex (1871), in From So Simple a Beginning: The Four Great Books of Charles Darwin, ed. Edward O. Wilson (New York: W. W. Norton, 1958), chaps. 3–5.
[3] Frederick Suppe, “The Search for Philosophic Understanding of Scientific Theories,” in The Structure of Scientific Theories, 2nd ed., ed. Frederick Suppe (Urbana: University of Illinois Press, 1977).
[4] Wool, David & Paz, Naomi & Friedman, Leonid. (2020). Darwin: The Descent of Man (1871). 10.1201/9781003023869-18.
[5] MacIntyre, Alasdair. (2007). After Virtue: A Study in Moral Theory.
[6] Halbig, Christoph. (2020). Virtue vs. virtue ethics. Zeitschrift für Ethik und Moralphilosophie. 3. 10.1007/s42048-020-00078-0.
[7] Douglas Adams, The Salmon of Doubt: Hitchhiking the Galaxy One Last Time (New York: Harmony, 2002), 99.
[8] Kinzebulatov, Damir. (2020). Regularity theory of Kolmogorov operator revisited. Canadian Mathematical Bulletin. 1-12. 10.4153/S0008439520000697
[9] Lack, Stephen & Tendas, Giacomo. (2019). Enriched regular theories. Journal of Pure and Applied Algebra. 224. 106268. 10.1016/j.jpaa.2019.106268.
[10] Berofsky, Bernard. (2012). The Regularity Theory I: Homean Supervenience. 10.1093/acprof:oso/9780199640010.003.0010.
[11] Ioannidis, John & Allison, David & Ball, Catherine & Coulibaly, Issa & Cui, Xiangqin & Culhane, Aedín & Falchi, Mario & Furlanello, Cesare & Game, Laurence & Jurman, Giuseppe & Mangion, Jon & Mehta, Tapan & Nitzberg, Michael & Page, Grier & Petretto, Enrico & van Noort, Vera. (2009). Repeatability of published microarray gene expression analyses. Nature genetics. 41. 149-55. 10.1038/ng.295.
[12] Artacho, Emilio. (2020). Changing the paradigm for research publishing. Physics Today. 73. 10-10. 10.1063/PT.3.4485.
[13] Miller, Joshua & Gelman, Andrew. (2020). Laplace’s Theories of Cognitive Illusions, Heuristics and Biases. Statistical Science. 35. 159-170. 10.1214/19-STS696.
[14] Molina Arias M. ¿Qué significa realmente el valor de p?. Rev Pediatr Aten Primaria. 2017;19:377-81. http://scielo.isciii.es/scielo.php?script=sci_arttext&pid=S1139-76322017000500014
[15] Winter, Bodo. (2019). Statistics for Linguists: An Introduction Using R. 10.4324/9781315165547.
[16] https://es.wikipedia.org/wiki/Valor_p
[17] Renner, Steffen & Bergsdorf, Christian & Bouhelal, Rochdi & Koziczak, Magdalena & Amati, Andrea & Techer-Etienne, Valerie & Flotte, Ludivine & Reymann, Nicole & Kapur, Karen & Hoersch, Sebastian & Oakeley, Edward & Schuffenhauer, Ansgar & Gubler, Hanspeter & Lounkine, Eugen & Farmer, Pierre. (2020). Gene-signature-derived IC50s/EC50s reflect the potency of causative upstream targets and downstream phenotypes. Scientific Reports. 10. 10.1038/s41598-020-66533-5.
[18] Wu, Xiangmei & Sun, Jing & Li, Liang. (2013). Chronic cerebrovascular hypoperfusion affects global DNA methylation and histone acetylation in rat brain. Neuroscience bulletin. 29. 10.1007/s12264-013-1345-8.
[19] Galvao, L. & Vitorello, Icaro & Paradella, Waldir. (2020). Spectroradiometric discrimination of laterites with principal componentes analysis.
[20] Doulah, Md. Siraj & Darwin, Charls & Salma, Ummi & Hamid, Abdul & Aktar, Mosfaka. (2020). Factor Analysis of Crime Data. 9. 20-32.
[21] Fanelli, Daniele. (2013). Positive results receive more citations, but only in some disciplines. Scientometrics. 94. 10.1007/s11192-012-0757-y.
[22] Klotz, Irving. (1980). The N-ray affair. Scientific American - SCI AMER. 242. 168-175. 10.1038/scientificamerican0580-168.
[23] Nye, Mary. (1980). N-Rays: An Episode in the History and Psychology of Science. Historical Studies in the Physical Sciences. 11. 125-156. 10.2307/27757473.
[24] Shearer, Karl. (2007). Experimental Design for Biologists. Quarterly Review of Biology - QUART REV BIOL. 82. 265-265. 10.1086/523125.
[25] Martens, Jean-bernard. (2020). Comparing experimental conditions using modern statistics. Behavior Research Methods. 1-22. 10.3758/s13428-020-01471-8.
[26] Gureyev, Vadim & Mazov, Nikolay & Kosyakov, Denis & Guskov, Andrey. (2020). Review and analysis of publications on scientific mobility: assessment of influence, motivation, and trends. Scientometrics. 124. 1599-1630. 10.1007/s11192-020-03515-4.
[27] Inanc, Ozlem & Tuncer, Onur. (2011). The Effect of Academic Inbreeding on Scientific Effectiveness. Scientometrics. 88. 885-898. 10.1007/s11192-011-0415-9
[28] Nosek, Brian & Alter, G. & Banks, George & Borsboom, Denny & Bowman, S. & Breckler, Steven & Buck, S. & Chambers, C. & Chin, G. & Christensen, G. & Contestabile, M. & Dafoe, A. & Eich, Eric & Freese, J. & Glennerster, R. & Goroff, D. & Green, Donald & Hesse, Bradford & Humphreys, M. & Yarkoni, T.. (2015). Self-correction in science at work. Science. 26. 1422-1425. 10.1126/science.aab3847.
Bruton, Sam & Medlin, Mary & Brown, Mitch & Sacco, Donald. (2020). Personal Motivations and Systemic Incentives: Scientists on Questionable Research Practices. Science and Engineering Ethics. 26. 10.1007/s11948-020-00182-9.
[29] Abt, Grant & Boreham, Colin & Davison, Gareth & Jackson, Robin & Nevill, Alan & Wallace, Eric & Williams, Mark. (2020). Power, precision, and sample size estimation in sport and exercise science research. Journal of Sports Sciences. 38. 10.1080/02640414.2020.1776002.
[30] Wichman, Chris & Smith, Lynette & Yu, Fang. (2020). A Framework for Clinical and Translational Research in the Era of Rigor and Reproducibility. Journal of Clinical and Translational Science. 1-37. 10.1017/cts.2020.523.
[31] Ratcliff, Chelsea & Jensen, Jakob & Christy, Kathryn & Crossley, Kaylee & Krakow, Melinda. (2018). News Coverage of Cancer Research: Does Disclosure of Scientific Uncertainty Enhance Credibility?.
Weinstein, Stuart. (2014). Raising the Bar for Science. PM & R : the journal of injury, function, and rehabilitation. 6. 293-4. 10.1016/j.pmrj.2014.03.007.
[32] Cho, Hae-Wol & Chu, Chaeshin. (2011). A Tale of Two Fields: Mathematical and Statistical Modeling of Infectious Diseases. Osong public health and research perspectives. 2. 73-4. 10.1016/j.phrp.2011.08.005.
Dempster, Arthur. (1998). Logicist Statistics I. Models and Modeling. Statistical Science. 13. 10.1214/ss/1028905887.
[33] Steiner, Stefan & Mackay, R.. (2017). Volume 29 Number 1 2017-Special Issue on the Fourth Stu Hunter Research Conference. Quality Engineering. 29. 1-1. 10.1080/08982112.2016.1260365.
Mehta, Sudhir & Danielson, Scott. (2002). Teaching Statics “Dynamically”.
[34] Kruschke, John. (2010). Doing Bayesian Data Analysis. Wiley Interdisciplinary Reviews: Cognitive Science. 1. 658 - 676. 10.1002/wcs.72.
Kim, Sungjin & Lee, Clarence & Gupta, Sachin. (2020). Bayesian Synthetic Control Methods. Journal of Marketing Research. 57. 002224372093623. 10.1177/0022243720936230.
Merdes, Christoph & Sydow, Momme & Hahn, Ulrike. (2020). Formal Models of Source Reliability. Synthese. 1-29.
D’Elia, C. & Carlson, S. & Stanfield, M. & Prime, Michael & Oliveira, Jeferson & Spradlin, T. & Lévesque, J.-B & Hill, Michael. (2020). Interlaboratory Reproducibility of Contour Method Data Analysis and Residual Stress Calculation. Experimental Mechanics. 60. 10.1007/s11340-020-00599-0.
[35] Marin, Francesca. (2017). On the Possibilities of Collaboration in the Valdés Peninsula: Fishers, Biologists, Anthropologists, and the Politics of Knowledge. Collaborative Anthropologies. 10. 124-141. 10.1353/cla.2017.0005.
[36] Couzin-Frankel J (2013). The power of negative thinking. Science 342(6154): 68–69.
[37] Maddox J, Randi J, Stewart WW (1988). ‘High-dilution’ experiments a delusion. Nature 334(6180): 287–291.
[38] Fisher RA (1971). The Design of Experiments. New York, NY: Hafner Publishing Company, 8th edn.
[39] Martinson BC, Anderson MS, de Vries R (2005). Scientists behaving badly. Nature 435(7043): 737–738.
[40] Fanelli D (2009). How many scientists fabricate and falsify research? A systematic review and meta-analysis of survey data. PLoS One 4(5): e5738.
[41] Witowski, Janusz & Sikorska, Dorota & Rudolf, András & Miechowicz, Izabela & Kamhieh-Milz, Julian & Jörres, Achim & Breborowicz, Andrzej. (2020). Quality of design and reporting of animal research in peritoneal dialysis: A scoping review. Peritoneal Dialysis International: Journal of the International Society for Peritoneal Dialysis. 40. 089686081989614. 10.1177/0896860819896148.
Reynolds, Robert & Lesko, Samuel & Gatto, Nicolle & Staa, Tjeerd & Mitchell, Allen. (2019). The Use of Randomized Controlled Trials in Pharmacoepidemiology. 10.1002/9781119413431.ch32.
[42] Dirnagl U (2006). Bench to bedside: the quest for quality in experimental stroke research. J Cereb Blood Flow Metab 26(12): 1465–1478.
[43] SHAZAM,. (2020). PVALUE: Calculating P-Values for Test Statistics Example.
Duckworth, W. & Mccabe, G. & Moore, Damian & Sclove, S. (2020). Statistical applets: P-Value of a test of significance.
[44] Campelo, Felipe & Wanner, Elizabeth. (2020). Sample size calculations for the experimental comparison of multiple algorithms on multiple problem instances. Journal of Heuristics. 10.1007/s10732-020-09454-w.
Lazic, Stanley & Mellor, Jack & Ashby, Michael & Munafo, Marcus. (2020). A Bayesian predictive approach for dealing with pseudoreplication. Scientific Reports. 10. 2366. 10.1038/s41598-020-59384-7.
[45] Lazic, Stanley & Essioux, Laurent. (2013). Improving basic and translational science by accounting for litter-to-litter variation in animal models. BMC neuroscience. 14. 37. 10.1186/1471-2202-14-37.
[46] Schnabel J (2008). Neuroscience: standard model. Nature 454(7205): 682–685.
[47] Benatar M (2007). Lost in translation: treatment trials in the SOD1 mouse and in human ALS. Neurobiol Dis 26(1): 1–13.
[48] Scott S, Kranz JE, Cole J, Lincecum JM, Thompson K, Kelly N, Bostrom A, Theodoss J, Al-Nakhala BM, Vieira FG, Ramasubbu J, Heywood JA (2008). Design, power, and interpretation of studies in the standard murine model of ALS. Amyotroph Lateral Scler 9(1): 4–15.
[49] Garcia-Berthou E, Alcaraz C (2004). Incongruence between test statistics and P values in medical papers. BMC Med Res Methodol 4: 13.
[50] Ganesh, Siva & Cave, Vanessa. (2017). P-values, p-values everywhere!. New Zealand Veterinary Journal. 66. 1-5. 10.1080/00480169.2018.1415604.
KOCAK, Mehmet. (2019). Null Distribution of P-values and an Empirical 'Uniformitization' Proposal. Turkiye Klinikleri Journal of Biostatistics. 11. 161-172. 10.5336/biostatic.2019-66871.
Hartgerink, Chris & Aert, Robbie & Nuijten, Michèle & Wicherts, Jelte & Assen, Marcel. (2016). Distributions of p-values smaller than .05 in psychology: What is going on?. PeerJ. 4. e1935. 10.7717/peerj.1935.
[51] Ramstrand, Nerrolyn & Fatone, Stefania & Dillon, Michael & Hafner, Brian. (2020). Sharing research data. Prosthetics and Orthotics International. 44. 49-51. 10.1177/0309364620915020.
Wicherts, Jelte & Bakker, Marjan & Molenaar, Dylan. (2011). Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results. PloS one. 6. e26828. 10.1371/journal.pone.0026828.
[52] Nieuwenhuis S, Forstmann BU, Wagenmakers EJ (2011). Erroneous analyses of interactions in neuroscience: a problem of significance. Nat Neurosci 14(9): 1105–1107.
[53] Stratton, Samuel. (2018). Significance: Statistical or Clinical?. Prehospital and Disaster Medicine. 33. 347-348. 10.1017/S1049023X18000663.
[54] Prinz F, Schlange T, Asadullah K (2011). Believe it or not: how much can we rely on published data on potential drug targets? Nat Rev Drug Discov 10(9): 712.
[55] Anglemyer AT, Krauth D, Bero L (2015). Industry sponsorship and publication bias among animal studies evaluating the effects of statins on atherosclerosis and bone outcomes: a meta-analysis. BMC Med Res Methodol 15(1): 12..
[56] Vassend, Olav. (2018). Goals and the Informativeness of Prior Probabilities. Erkenntnis. 83. 1-24. 10.1007/s10670-017-9907-1.
[57] Fanelli D (2012). Negative results are disappearing from most disciplines and countries. Scientometrics 90(3): 891–904.
[58] Djulbegovic B, Kumar A, Glasziou P, Miladinovic B, Chalmers I (2013). Medical research: trial unpredictability yields predictable therapy gains. Nature 500(7463): 395–396.
[59] Gonzalez Ochoa, Alejandro. (2020). Reducing Hyperpigmentation After Sclerotherapy: Results of a Prospective, Multicenter, Randomized Trial. Journal of Vascular Surgery. 72. e15. 10.1016/j.jvs.2020.04.036.
[60] Motulsky, Harvey. (2015). Common misconceptions about data analysis and statistics. Pharmacology Research and Perspectives. 3. 1-8. 10.1002/prp2.93.
[61] Godfroid, Aline. (2019). General Principles of Experimental Design. 10.4324/9781315775616-5.
[62] Yanco, Scott & McDevitt, Andrew & Trueman, Clive & Hartley, Laurel & Wunder, Michael. (2020). A modern method of multiple working hypotheses to improve inference in ecology. Royal Society Open Science. 7. 200231. 10.1098/rsos.200231.
[63] Prochilo, Guy & Louis, Winnifred & Bode, Stefan & Zacher, Hannes & Molenberghs, Pascal. (2019). An Extended Commentary on Post-publication Peer Review in Organizational Neuroscience. 3. 10.15626/MP.2018.935.
[64] Urlings, Miriam & Duyx, Bram & Swaen, Gerard & Bouter, Lex & Zeegers, Maurice. (2020). Determinants of Citation in Epidemiological Studies on Phthalates: A Citation Analysis. Science and Engineering Ethics. 10.1007/s11948-020-00260-y.
[65] Mulder, Gerben. (2020). The New Statistics for applied linguistics. Dutch Journal of Applied Linguistics. 10.1075/dujal.19019.mul.
Kim, Jae-Hoon & Choi, In. (2019). Choosing the Level of Significance: A Decision-theoretic Approach. Abacus. 10.1111/abac.12172.
[66] Perneger TV, Courvoisier DS (2010). Interpretation of evidence in data by untrained medical students: a scenario-based study. BMC Med Res Methodol 10: 78.
Weinberg, Clarice. (2001). It???s Time to Rehabilitate the P-Value. Epidemiology. 12.288-290.10.1097/00001648-200105000-00004.
[67] Lecoutre MP, Poitevineau J, Lecoutre B (2003). Even statisticians are not immune to misinterpretations of null hypothesis significance tests. Int J Psychol 38(1): 37–45.
[68] Rosenthal R, Gaito J (1963). The interpretation of levels of significance by psychological researchers. J Psychol 55: 33–38.
[69] Mayo DG (1996). Error and the Growth of Experimental Knowledge. Chicago, IL: Chicago University Press.
[70] Weinberg CR (2001). It’s time to rehabilitate the P-value. Epidemiology 12(3): 288–290.
[71] Cumming G (2012). Understanding the New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analysis. New York, NY: Routledge.
[72] Hoekstra R, Morey RD, Rouder JN, Wagenmakers EJ (2014). Robust misinterpretation of confidence intervals. Psychon Bull Rev 21(5): 1157–1164.
[73] Morey RD, Hoekstra R, Rouder JN, Lee MD, Wagenmakers EJ (2016). The fallacy of placing confidence in confidence intervals. Psychon Bull Rev 23(1): 103–123.
[74] Jaynes ET (2003). Probability Theory: The Logic of Science. Cambridge, UK: Cambridge University Press.
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Berenice Yahuaca Juárez
Erasmo Cadenas Calderón
Abraham Zamudio Durán
Lizbeth Guadalupe Villalon Magallan
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán
Monica Rico Reyes