Texto universitario

_____________________________
CAPÍTULO 4. Evaluación de datos analíticos
4.1 Introducción
El campo de análisis de alimentos, o cualquier tipo de análisis, implica una cantidad considerable de tiempo para aprender los principios, métodos y operación de los instrumentos y el perfeccionamiento de diversas técnicas. Aunque estas áreas son extremadamente importantes, gran parte de nuestro esfuerzo sería en vano si no hubiese alguna manera de evaluar los datos obtenidos de los diversos ensayos analíticos. Varios tratamientos matemáticos están disponibles, estos proporcionan una idea de lo bien que se llevó a cabo en un ensayo particular o qué tan bien puede ser reproducido un experimento. Afortunadamente, las estadísticas se encuentran involucradas, y son la mayoría de las determinaciones analíticas las que indican el grado de éxito alcanzado en el procedimiento.
Si los datos analíticos se recogen en un laboratorio de investigación o en la industria alimentaria, las decisiones importantes se toman con base en los datos. La apropiada recopilación de datos y su análisis ayudará a evitar las malas decisiones que se realizan en consideración a los datos. Tener una buena comprensión de los datos y cómo deben ser interpretados (por ejemplo, qué números son estadísticamente uniformes) resulta fundamental para una buena toma de decisiones. Hablando estadísticamente, antes de diseñar experimentos o pruebas a los productos producidos con una correcta recolección de datos y su adecuado análisis, puede mejorar significativamente la toma de decisiones.
El enfoque en este apartado se centra principalmente en la forma de evaluar análisis repetidos de la misma muestra con exactitud y precisión. Además, se da una atención considerable a la determinación de la mejor línea de ajuste de datos a la curva estándar. Tenga en cuenta al leer y trabajar a través de este apartado que hay una amplia gama de softwares de ordenador para realizar la mayoría de los tipos de evaluación de datos y cálculos, recomendando emplear lenguaje R. El muestreo y tamaño apropiado de la muestra se tratan en el siguiente apartado.
4.2 Medidas de tendencia central
Para aumentar la exactitud y precisión, así como para evaluar estos parámetros, el análisis de una muestra se realiza generalmente en repetidas veces. Al menos tres ensayos se realizan típicamente, aunque a menudo el número puede ser mucho mayor. Debido a que no estamos seguros de qué valor es el más cercano al valor verdadero, determinamos la media (o promedio) utilizando todos los valores obtenidos e informamos los resultados de la media. La media se designa por el símbolo ![]() y calculada según la siguiente ecuación:
y calculada según la siguiente ecuación:
Ec. 4.1
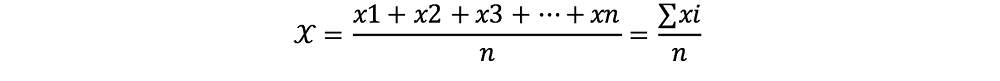
Donde:
![]() = representa el promedio
= representa el promedio
X1, X2, etc. = valores medidos individualmente (Xi)
n = número de mediciones
Por ejemplo, supongamos que mide una muestra de pan sin cocer para evaluar el contenido de humedad (en porcentaje) en cuatro veces repetidas, obteniéndose los siguientes resultados: 64.53%, 64.45%, 65.10% y 64.78%:
Ec. 4.2
![]()
Por lo tanto, el resultado sería reportado como 64,72% de humedad. Cuando se presenta el valor de la media, estamos indicando que esta es la mejor estimación del valor experimental. No estamos diciendo nada acerca de qué tan exacto o verdadero es este valor. Algunos de los valores individuales pueden estar más cerca al valor verdadero, pero no hay manera de hacer esa determinación, así que solo se informa la media.
Otra determinación que se puede utilizar es la mediana, que es el número del punto medio o media dentro de un grupo de números. Básicamente, la mitad de los valores experimentales será menor que la mediana y la media será mayor. La mediana no se utiliza a menudo, porque la media es un estimador experimental superior.
4.3 Fiabilidad del análisis
Volviendo a nuestro ejemplo anterior, recordemos que se obtuvo el valor de la media de humedad. Sin embargo, no tenemos ninguna indicación de qué tan reproducibles eran las pruebas o qué tan cercanos son nuestros resultados al valor verdadero.
4.3.1 Exactitud y precisión
Uno de los aspectos más confusos de análisis de datos para los estudiantes es el prejuicio a los conceptos de exactitud y precisión. Estos términos son comúnmente utilizados indistintamente en la sociedad, lo que solo incrementa esta confusión. Si tenemos en cuenta el propósito del análisis, a continuación, estos términos se vuelven mucho más claros. Si lo observamos desde nuestros experimentos, sabemos que los primeros datos obtenidos son los resultados individuales y su promedio ![]() un valor medio de todos ellos. Las siguientes preguntas deben ser: ¿qué tan cercanas fueron nuestras mediciones individuales? y ¿qué tan cerca estaban estas del valor verdadero? Ambas preguntas implican los conceptos exactitud y precisión en los que ahora centraremos nuestra atención.
un valor medio de todos ellos. Las siguientes preguntas deben ser: ¿qué tan cercanas fueron nuestras mediciones individuales? y ¿qué tan cerca estaban estas del valor verdadero? Ambas preguntas implican los conceptos exactitud y precisión en los que ahora centraremos nuestra atención.
Exactitud se refiere a qué tan cercana es una medida particular al valor verdadero o correcto. En el análisis del pan, recordamos que obtuvimos una media de 64.72% de humedad. Digamos que el verdadero valor de la humedad era en realidad un 65.05%. Mediante la comparación de estos dos números, probablemente podríamos hacer una conjetura de que los resultados eran bastante exactos porque estaban cercanos al valor correcto.
El problema en la determinación de la exactitud es que la mayoría de las veces no estamos seguros de cuál es el verdadero valor. Para ciertos tipos de materiales, podemos adquirir muestras conocidas de, por ejemplo, el Instituto Nacional de Estándares y Tecnología y comprobar nuestros ensayos en referencia a estas muestras. Solo entonces podremos tener una indicación de la precisión de los procedimientos experimentales de prueba. Otro método consiste en comparar nuestros resultados con los de otros laboratorios para determinar qué tan bien están acorde a lo esperado, suponiendo que los otros laboratorios son exactos.
Un término que es mucho más fácil de tratar y determinar, es la precisión. Este parámetro es una medida de cuán reproducible o cercano al desarrollar mediciones repetidas es el valor. Si pruebas repetitivas producen resultados similares, entonces diríamos que la precisión de la prueba fue buena. Desde un cierto punto de vista estadístico, la precisión a menudo se refiere al error, cuando en realidad estamos apreciando la variación experimental. Por lo tanto, los conceptos de precisión, error y variación están estrechamente relacionados.
La diferencia entre precisión y la exactitud se puede ilustrar mejor con la Fig. 4.1. Imagínese disparar un rifle a un blanco que representa los valores experimentales. El ojo del aro sería el verdadero valor, y donde golpean las balas representaría los valores experimentales individuales. Como se puede ver en la Fig. 4.1a, Los valores pueden estar estrechamente espaciados (buena precisión) y cerca de la media (buena exactitud), o, en algunos casos, puede haber situaciones con buena precisión, pero poca exactitud (Fig. 4.1b). La peor situación, como se ilustra en la Fig.4.1d, es cuando tanto la exactitud y la precisión están ausentes. En este caso, debido a errores o variación en la determinación, la interpretación de los resultados se hace muy difícil. Más tarde, se discutirán los aspectos prácticos de los diferentes tipos de errores.
 19.04.09.png) Figura 4.1 Comparación de exactitud y precisión: (a) buena exactitud y una buena precisión, (b) buena precisión y exactitud ausente, (c) buena exactitud y precisión ausente, y (d) exactitud y precisión ausentes.
Figura 4.1 Comparación de exactitud y precisión: (a) buena exactitud y una buena precisión, (b) buena precisión y exactitud ausente, (c) buena exactitud y precisión ausente, y (d) exactitud y precisión ausentes.
Al evaluar los datos en varias pruebas, se utilizan comúnmente indicadores de precisión, para dar una apreciación de cuánto variarían los valores experimentales si tuviéramos que repetir las pruebas. Una manera fácil de mirar a la variación o dispersión es reportar el rango de los valores experimentales. El rango es simplemente la diferencia entre la mayor y la menor observación. Esta medida no es demasiado útil y por tanto rara vez se utiliza en la evaluación de datos.
Probablemente la mejor y más comúnmente utilizada evaluación del análisis estadístico de la precisión de los datos es la desviación estándar. La desviación estándar mide la dispersión de los valores experimentales y da una buena indicación de lo cerca que los valores están el uno del otro. Al evaluar la desviación estándar, hay que recordar que nunca seremos capaces de analizar la totalidad del producto alimenticio. Eso sería difícil, si no imposible, y conllevaría mucho tiempo. Por lo tanto, los cálculos que utilizamos son solo estimaciones del valor verdadero desconocido.
Si tenemos muestras, entonces la desviación estándar está designada por la letra griega sigma (σ). Se calcula según la ecuación 4.3. Suponiendo que todo el producto alimenticio se evaluó, lo que sería una cantidad infinita de ensayos experimentales, pero en la práctica n es un valor entero del subconjunto del universo:
Ec. 4.3
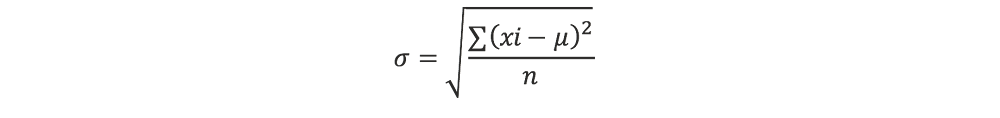
Donde
= desviación estándar
xi= valores de las muestras individuales
![]() = media verdadera
= media verdadera
n = población total de muestras
Debido a que no conocemos el valor de la media verdadera, la ecuación se simplifica para que podamos utilizarlo con datos reales. En este caso, lo que ahora llamamos σ o SD representa el término de desviación estándar de la muestra. Se determina de acuerdo con el cálculo de la ecuación. 4.4, donde ![]() reemplaza el término medio verdadero μ y n representa el número de muestras:
reemplaza el término medio verdadero μ y n representa el número de muestras:
Ec. 4.4
![]()
Si el número de determinaciones replicadas es pequeño (alrededor de 30 o menos), que es común con la mayoría de los ensayos, la n se sustituye por el n-1, y la ecuación 4.5 es aplicada. A menos que conozca lo contrario, la ecuación 4.5 siempre se utiliza en el cálculo de la desviación estándar de un grupo de ensayos pequeños:
Ec. 4.5
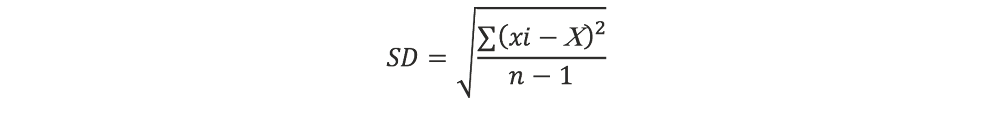
Dependiendo de cuál de las ecuaciones anteriores se utiliza, la desviación estándar puede ser reportada como SDn o σn y SDn-1 o σn-1. (Las diferentes marcas de software y calculadoras científicas a veces usan diferentes etiquetas para las teclas, por lo que hay que tener cuidado). La tabla 4.1 muestra un ejemplo de la determinación de la desviación estándar. Los resultados de la muestra se expresarían con una media de 64.72% de humedad con una desviación estándar de 0.293.
Una vez que tenemos la media y la desviación estándar, debemos profundizar en determinar cómo interpretar estos números. Una manera fácil de obtener una idea de la desviación estándar es calcular lo que se llama el coeficiente de variación (CV), también conocido como desviación estándar relativa. El cálculo mostrado a continuación ejemplifica nuestro ejemplo de la determinación de la humedad en pan:
Ec. 4.6
![]()
Ec. 4.7
![]()
El CV nos dice que nuestra desviación estándar es solamente superior a la media. Para nuestro ejemplo, el número es pequeño, lo que indica un alto nivel de precisión o reproducibilidad de las repeticiones. Como regla general, un CV inferior al 5%, se considera aceptable, aunque depende del tipo de análisis.
Tabla 4.1 Determinación de la desviación estándar de porcentaje de humedad en pan sin cocer.
 19.08.20.png)
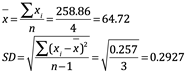
Otra forma de evaluar el significado de la desviación estándar es examinar su origen en la teoría estadística. Muchas poblaciones (en nuestro caso, los valores de muestra o media) se dice que existen en la naturaleza para tener una distribución normal. Si tuviéramos que medir un número infinito de muestras, obtendríamos una distribución similar a la representada en la Fig. 4.2. En una población con una distribución normal, 68% de aquellos son valores dentro de ±1 desviación estándar de la media, 95% sería dentro de ±2 desviaciones estándar, y 99,7% sería dentro de ±3 desviaciones estándar. En otras palabras, hay una probabilidad de menos del 1% de que una muestra en una población caería fuera de ±3 desviaciones estándar del valor medio.
Otra forma de entender la curva de distribución normal es darse cuenta de que la probabilidad de encontrar la media verdadera está dentro de ciertos intervalos de confianza como se define por la desviación estándar. Para un gran número de muestras, podemos determinar el Límite de confianza o intervalo alrededor de la media utilizando el parámetro estadístico llamado valor Z. Hacemos este cálculo, primero buscando el valor Z de tablas estadísticas, una vez que hemos decidido el grado deseado de certeza. Algunos valores Z se enumeran en la tabla 4.2.
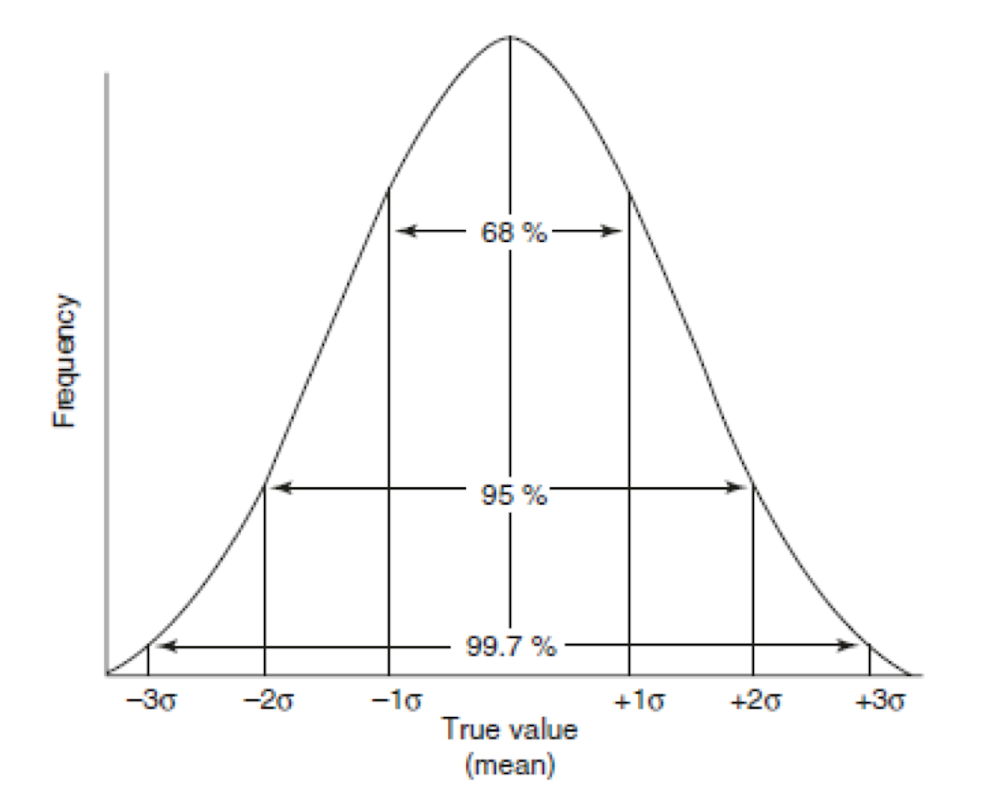
Figura 4.2 Distribución normal de la curva para una población de cuatro grupos de análisis.
Tabla 4. 2 Los valores de Z para el control de ambos niveles superior e inferior.
 19.11.34.png)
El límite de confianza (o intervalo) para nuestros datos de humedad, asumiendo una probabilidad del 95%, se calcula según la ecuación. 4.8. Dado que este cálculo no es válido para números pequeños, nosotros asumimos 25 muestras en vez de cuatro:
Ec. 4.8, Ec. 4.9,

Debido a que nuestro ejemplo tenía solo cuatro valores para el contenido de humedad, el intervalo de confianza debe ser calculado utilizando tablas estadísticas. En este caso, tenemos que buscar el valor ten la Tabla 4.3 basado en el grado de libertad, que es el tamaño de la muestra menos uno (n - 1), y el nivel deseado de confianza.
El cálculo para nuestro ejemplo, la humedad con cuatro muestras (n) y tres grados de libertad (n- 1) es la siguiente:
Ec. 4.10, Ec. 4.11

Para interpretar este número, podemos decir que, con una confianza del 95%, la media real para nuestro % de humedad caerá dentro de 64,72 ± 0.465% o entre 65.185% y 64.255%.
La expresión ![]() a menudo se presenta como el error estándar de la media. A continuación, se deja al lector para calcular el intervalo de confianza basado en el nivel deseado de certeza.
a menudo se presenta como el error estándar de la media. A continuación, se deja al lector para calcular el intervalo de confianza basado en el nivel deseado de certeza.
Otras pruebas rápidas de precisión utilizadas son la desviación relativa de la media y promedio relativo de desviación de la media. La desviación relativa de la media es útil cuando se han realizado solo dos repeticiones. Se calcula según la ecuación 4.12, los valores inferiores al 2% se consideran aceptables:
Tabla 4.3 Valores para t para varios niveles de probabilidad.
 19.13.26.png)
* Tablas más extensivas para los valores de t pueden ser encontradas en libros de estadística.
Desviación relativa de la media
Ec. 4.12
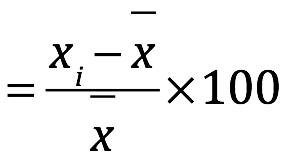
Donde:
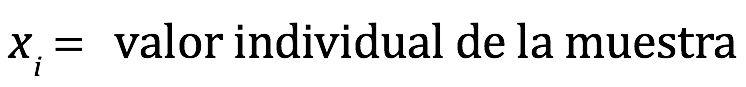
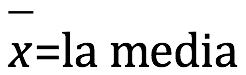
Si hay varios valores experimentales, entonces el promedio relativo de la desviación media se convierte en un indicador útil de precisión. Se calcula de manera similar a la desviación relativa de la media, excepto que la desviación media se utiliza en lugar de la desviación individual. Se calcula según la ecuación 4.13 :
Promedio relativo de la desviación media.
Ec. 4.13
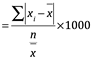
= Partes por mil
Usando los valores de humedad discutidos en la Tabla 4.1, los términos ![]() para cada determinación son -0.19, 0.27, +0.38, y +0.06. Entonces el cálculo se convierte:
para cada determinación son -0.19, 0.27, +0.38, y +0.06. Entonces el cálculo se convierte:
Ec.4.14
Promedio relativo de la desviación media=

Hasta ahora, las discusiones de los cálculos tienen formas interesantes para evaluar la precisión. Si el valor real no se conoce, se puede calcular solamente la precisión. Con un bajo grado de precisión, sería difícil de predecir un valor realista para la muestra.
Sin embargo, es posible que en ocasiones se tenga una muestra para la que conocemos el valor verdadero y podemos comparar nuestros resultados con el valor conocido. En este caso, podemos calcular el error de nuestra prueba, compararlo con el valor conocido, y determinar la exactitud. Un término que se puede calcular es el error absoluto, que es simplemente la diferencia entre el valor experimental y el valor verdadero:
Ec. 4.15
![]()
Donde:
x = valor determinado experimentalmente
T = valor verdadero
El término de error absoluto puede corresponder a un valor positivo o negativo. Si el valor determinado experimentalmente es de varias repeticiones entonces la media (0) sería sustituido por el término χ. Esta no es una buena prueba para el error, ya que el valor no está relacionado con la magnitud del valor verdadero. Una medición más útil de error es la estimación del error relativo:
Ec. 4.16
![]()
Los resultados se reportan como un valor negativo o positivo, lo que representa una fracción del valor verdadero. Si se desea, el error relativo puede expresarse como porcentaje de error relativo multiplicado por 100%. Entonces la relación se convierte en la siguiente, donde puede ser o bien una determinación individual o la media (0) de varias determinaciones:
Ec. 4.17
![]()
Usando los datos para el porcentaje de humedad del pan sin cocer, supongamos que el valor verdadero de la muestra es 65,05%. El error relativo porciento se calcula utilizando nuestro valor medio de 64,72% y la ecuación 4.17:
Ec. 4.18
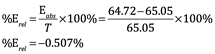
Tenga en cuenta que mantenemos el valor negativo, lo que indica la dirección de nuestro error, es decir, nuestros resultados fueron 0.507% menores que el valor verdadero.
4.3.2 Fuentes de errores
Como se recordará de las discusiones de exactitud y precisión, el error (variación) puede ser muy importante en las determinaciones analíticas. Aunque nos esforzamos para obtener resultados correctos, es irrazonable esperar que una técnica analítica se encuentre completamente libre de errores. Lo mejor que podemos esperar es que la variación sea pequeña y, si es posible, al menos consistente. Mientras que esperamos saber acerca del error, un método analítico a menudo será satisfactorio. Hay varias fuentes de error, que se pueden clasificar como, error sistemático (determinado), error aleatorio (indeterminado), y error grave o una serie de errores. Una vez más, tenga en cuenta que error y variación se utilizan indistintamente en esta sección y esencialmente tienen el mismo significado para estas discusiones.
Un error sistemático o determinado produce resultados con desviaciones constantes a partir del valor esperado en un sentido o en el otro. Como se ilustra en la Fig. 4.1b, los resultados están espaciados estrechamente, pero son consistentes fuera del objetivo. Identificar el origen de este grave tipo de error puede ser difícil y requiere mucho tiempo, porque implica a menudo la implicación de instrumentos inexactos o aparatos de medición descalibrados. Por ejemplo, una pipeta que entrega constantemente el volumen incorrecto de reactivo producirá un alto grado de precisión aún cuando todos sean resultados inexactos. A veces los productos químicos impuros o el método de análisis en sí pueden ser la causa. En general, podemos superar los errores sistemáticos mediante la calibración adecuada de los instrumentos, corriendo determinaciones en referencia blanco y control, o utilizando un método analítico de referencia diferente.
Errores aleatorios o indeterminados siempre están presentes en cualquier medición analítica. Este tipo de error es debido a nuestras limitaciones naturales en la medición de un sistema en particular. Estos errores fluctúan de una manera aleatoria y son esencialmente inevitables. Por ejemplo, en la lectura de una balanza analítica; al juzgar el cambio de punto final en una concentración, y en el uso óptimo de una pipeta; todo contribuye a la creación del error aleatorio. Antecedentes en el ritmo de operación del instrumento, siempre están presentes en cierto grado, son un factor en el error aleatorio. Ambos errores positivos y negativos son igualmente posibles. Aunque este tipo de error es difícil de evitar, afortunadamente suelen ser relativamente pequeños.
Una serie de errores que residen en el mismo origen de medición, por lo general son pequeñas equivocaciones fáciles de eliminar, ya que resultan evidentes. Los datos experimentales son generalmente dispersos, y los resultados no están cerca del valor esperado. Este tipo de error es el resultado de utilizar el reactivo incorrecto o instrumento o de la técnica en modo descuidado. Algunas personas han llamado a este tipo de error, el error del “síndrome del lunes por la mañana”. Afortunadamente estos errores se identifican y se corrigen fácilmente.
4.3.3 Especificidad
La especificidad de un método de análisis en particular, significa que detecta solamente el componente de interés. Los métodos de análisis pueden ser muy específicos para un determinado alimento o componente, en muchos casos, pueden llegar a analizar un amplio espectro de componentes. Muy a menudo, es deseable que el método sea de amplio espectro en su sensibilidad de detección. Por ejemplo, la determinación de lípidos de alimentos (grasas) es en realidad el análisis crudo de cualquier compuesto que es soluble en un disolvente orgánico. Algunos de estos compuestos son los glicéridos, fosfolípidos, carotenos, y ácidos grasos libres. Puesto que no nos preocupa cada compuesto en lo individual al considerar el contenido de grasa cruda de los alimentos, es deseable que el método sea de amplio alcance. Por otra parte, la determinación del contenido de lactosa en un helado requeriría un método específico. Debido a que el helado contiene otros tipos de azúcares simples, y sin un método específico no podría estimarse la cantidad de lactosa presente en la muestra.
No hay reglas rígidas en lo que a especificidad requerida se refiere. Cada situación es diferente y depende de los resultados deseados y el tipo de ensayo utilizado. Sin embargo, es algo a tener en consideración cuando se analizan las diversas técnicas analíticas.
4.3.4 La sensibilidad y límite de detección
Aunque se usan a menudo de forma intercambiable, los términos de sensibilidad y límite de detección no deben ser confundidos. Estos tienen diferentes significados, y sin embargo, están estrechamente relacionados. Sensibilidad, se refiere a la magnitud del cambio de un dispositivo de medición (instrumento) con cambios en la concentración del compuesto. Es un indicador de que un pequeño cambio puede tener lugar en el material desconocido antes de percatarnos de una diferencia en un medidor de aguja o un lector digital. Todos estamos familiarizados con el proceso de sintonizar una emisora de radio en nuestro equipo de música y sabemos cómo, en algún momento, una vez que la estación está sintonizada, podemos mover el dispositivo sin perturbar la recepción. Esta es la sensibilidad. En muchas situaciones, podemos ajustar la sensibilidad de un ensayo para adaptarse a nuestras necesidades, es decir, si queremos más o menos sensibilidad. Incluso podríamos desear una menor sensibilidad, de modo que las muestras con concentraciones muy variables pueden ser analizadas al mismo tiempo[1].
El límite de detección (LOD), en contraste con la sensibilidad, es el incremento más bajo posible en que podemos detectar con cierto grado de confianza (o significación estadística). Con cada ensayo, hay un límite inferior y en ese momento no estamos seguros de si algo está presente o no. Obviamente, la mejor opción sería la de concentrar la muestra de modo que no estemos trabajando cerca del límite de detección. Sin embargo, esto no puede ser posible en la mayoría de los casos, y tal vez se necesite saber el límite de detección para que podamos trabajar fuera de ese límite.
Hay varias formas de medir LOD, dependiendo del aparato que se utilice. Si estamos utilizando algo como un espectrofotómetro, cromatografía de gases o cromatografía líquida de alto rendimiento (HPLC), el LOD a menudo se alcanza cuando la relación señal-ruido es 3 o mayor[2]. En otras palabras, cuando la muestra da un valor que es tres veces la magnitud de la detección de ruido, el instrumento está en el límite más bajo posible. El ruido es la fluctuación de señal aleatoria que ocurre con cualquier instrumento.
Una forma más general de definir el límite de detección es desde un enfoque estadístico, en el que se considera la variación entre muestras. Una definición matemática representa un modo acertado de definir el límite de detección:
Ec. 4.19
![]()
Donde:

En esta ecuación, la variación en los valores del blanco (o ruido en referencia a los instrumentos) determina el límite de detección. Una alta variabilidad en los valores del blanco reduce el límite de detección y abre paso a dudar de la confiabilidad del ensayo.
Otro método que abarca el método del ensayo entero, es el límite de detección del método MDL. De acuerdo con la Agencia de Protección ambiental de los EE.UU., el MDL es definido como “la concentración mínima de una sustancia que puede ser medida y reportada con un 99% de confianza de la que su concentración analítica es mayor que cero, y la cantidad es determinada por un análisis de una muestra que involucra una matriz que contiene el analito”, lo que diferencia el MDL de la LOD es que incluye la totalidad del ensayo y varios tipos de muestras corrigiendo así la variabilidad a lo largo del procesamiento[3]. El MDL se calcula basándose en los valores de las muestras dentro de la matriz de ensayo y por lo tanto se considera una prueba de rendimiento más riguroso. Los procedimientos sobre cómo configurar el MDL se explican en las regulaciones de la EPA sobre pruebas ambientales.
Aunque la LOD o MDL es a menudo suficiente para caracterizar un ensayo, una evaluación adicional a considerar es el límite de cuantificación (LOQ). En esta determinación se recogen datos similares a los del LOD a excepción de que el valor es determinado como:
![]()
4.3.5 Medidas de Control de Calidad
En el control de calidad/garantía es deseable evaluar el rendimiento de un análisis, un método o un proceso. Para explicar cómo los datos y gráficos de control analítico pueden ser utilizados en la industria alimentaria para Control del Proceso Estadístico, este apartado describirá brevemente el control de calidad desde la perspectiva de la monitorización de un proceso específico en la fabricación de un producto alimenticio (por ejemplo, el secado de un producto, lo que afecta el contenido de humedad final). Si el proceso está bien definido y se conoce su variabilidad, los datos analíticos recogidos pueden ser evaluados en tiempo. Esto proporciona un conjunto de puntos de control para determinar si el proceso está funcionando como estaba previsto. Dado que todos los procesos son susceptibles de cambio o de ser obsoletos, una decisión puede ser tomada para ajustar el proceso.
La mejor manera de evaluar el control de calidad es mediante una cartografía de control. Esto implica trazado secuencial de las observaciones medias (por ejemplo, el contenido de humedad) obtenidas del análisis junto con un valor objetivo. La desviación estándar a continuación, se utiliza para determinar los límites aceptables en el nivel de confianza del 95% o 99%, y en el punto en que los datos están fuera de la gama de valores aceptables. A menudo, los límites aceptables se establecen como dos desviaciones estándar a cada lado de la media, con los límites de acción fijados en tres desviaciones estándar. Los gráficos y los límites se utilizan para determinar si se ha producido una variación que se encuentra fuera de la variación normal para el proceso. Si esto ocurre, hay una necesidad de determinar la causa de la variación y poner en marcha las acciones correctivas y preventivas para mejorar aún más el proceso.
Dos tipos comunes de gráficos de control utilizados, son los gráficos Shewhart y CuSum descritos por Ellison[4]. El gráfico CuSum puede percibirse más complicado y es mejor poner de relieve los pequeños cambios en el valor medio. El gráfico Shewhart (Fig. 4.3) implica gráficos del significado del valor objetivo y ambos límites superior e inferior para cada medición. Se determinan y agregan un límite de advertencia superior e inferior y un límite de acción al gráfico[5]. El límite de advertencia muestra que las mediciones pueden estar saliendo del límite deseable (por ejemplo, una tendencia al alza). El límite de acción indica que las mediciones han pasado el límite aceptable, por lo que el proceso debe evaluarse para determinar las causas de la deriva. Los cálculos y gráficos se proporcionan en las referencias[6].
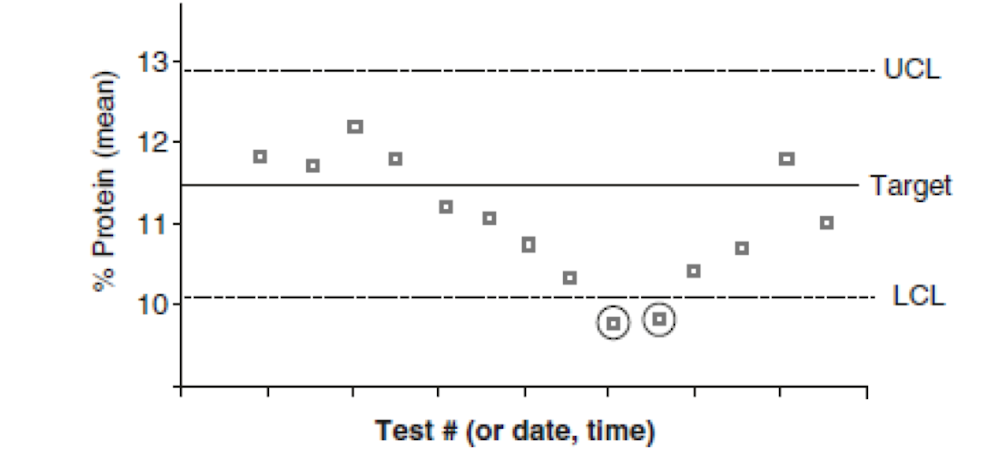
Figura 4.3 Un ejemplo de un gráfico de control Shewhart para el análisis de proteínas. El límite de control superior (UCl) y límite de control inferior (LCL) están predeterminados. Los valores que caen fuera de los límites (los valores encerrados en un círculo) indican que el ensayo requiere tomar acciones y necesita ser corregido o ajustado.
El límite de advertencia indica que las mediciones pueden estar moviéndose fuera del límite deseable (por ejemplo, tendencia al alza). El límite de acción indica que las mediciones son más allá del límite aceptable por lo que el proceso tiene que ser evaluado para las causas de la deriva.
4.4 Ajuste de la curva: análisis de regresión
El ajuste de curvas es un término genérico usado para describir la relación y la evaluación entre dos variables. La mayoría de los campos científicos utilizan procedimientos de ajuste de curvas para evaluar la relación entre dos variables. Por lo tanto, el ajuste de la curva o el análisis apropiado curvilíneo de datos es un área extensa como lo demuestran los volúmenes de material que describen estos procedimientos en la literatura clásica. En determinaciones analíticas, estamos usualmente preocupados por solo un pequeño segmento del análisis curvilíneo, la curva estándar o regresión lineal[7].
Una curva estándar o curva de calibración se utiliza para determinar concentraciones desconocidas con base a un método que da algún tipo de respuesta medible que es proporcional a una cantidad conocida del estándar. Por lo general implica la realización de un grupo de estándares conocidos en concentración creciente y luego grabar el parámetro analítico particular medido (por ejemplo, absorbancia, área de un pico de cromatografía, etc.). Lo que resulta cuando graficamos el emparejado de los valores x-y es un gráfico de dispersión de puntos que pueden ser unidos entre sí para formar una línea recta que relaciona la concentración a la respuesta observada. Una vez que sabemos cómo los valores observados cambian con la concentración, es bastante fácil de estimar la concentración de un componente en una muestra desconocida por interpolación en la curva estándar.
A medida que lea los tres apartados siguientes, tenga en cuenta que no todas las correlaciones de los valores observados respecto a concentraciones estándar son lineales (pero la mayoría lo son). Hay muchos ejemplos de curvas no lineales, tales como la de unión de antígenos-anticuerpo, las evaluaciones de toxicidad, y de crecimiento exponencial y decadencia. Afortunadamente, con la gran variedad de programas informáticos disponibles en la actualidad, es relativamente fácil de analizar cualquier grupo de datos.
4.4.1 Regresión lineal
Entonces, ¿cómo configurar una curva estándar una vez que se han recogido los datos? En primer lugar, la decisión debe ser tomada con respecto a qué eje trazar los conjuntos de pares de datos. Tradicionalmente, la concentración de los estándares está representado en el eje x, y las lecturas observadas están en el eje y. Sin embargo, este protocolo se usa por razones distintas de convención, los datos del eje x se denominan la variable independiente y se supone que son esencialmente libres de errores, mientras que los datos del eje y (la variable dependiente) pueden tener errores asociados con ellos. Esta suposición puede no ser cierta porque el error podría ser incorporado cuando se hacen en los estándares. Con los instrumentos de hoy en día, el error puede ser muy pequeño. Aunque se puede argumentar para hacer el eje y, como datos de concentración, para todos los propósitos prácticos, el resultado final es esencialmente el mismo. A menos que existan algunos datos inusuales, la concentración debe estar asociada con el eje x y los valores medidos con el eje y.
La Figura 4.4, ilustra una curva estándar típica utilizada en la determinación de la cafeína en diversos alimentos. La cafeína se analiza fácilmente en los alimentos mediante el uso de HPLC junto con un detector ultravioleta ajustado a 272 nm. El área bajo el pico de cafeína a 272 nm es directamente proporcional a la concentración. Cuando una muestra es desconocida (por ejemplo, café) se ejecuta en la HPLC, un área de pico puede ser obtenida empleando la curva estándar de la muestra[8].
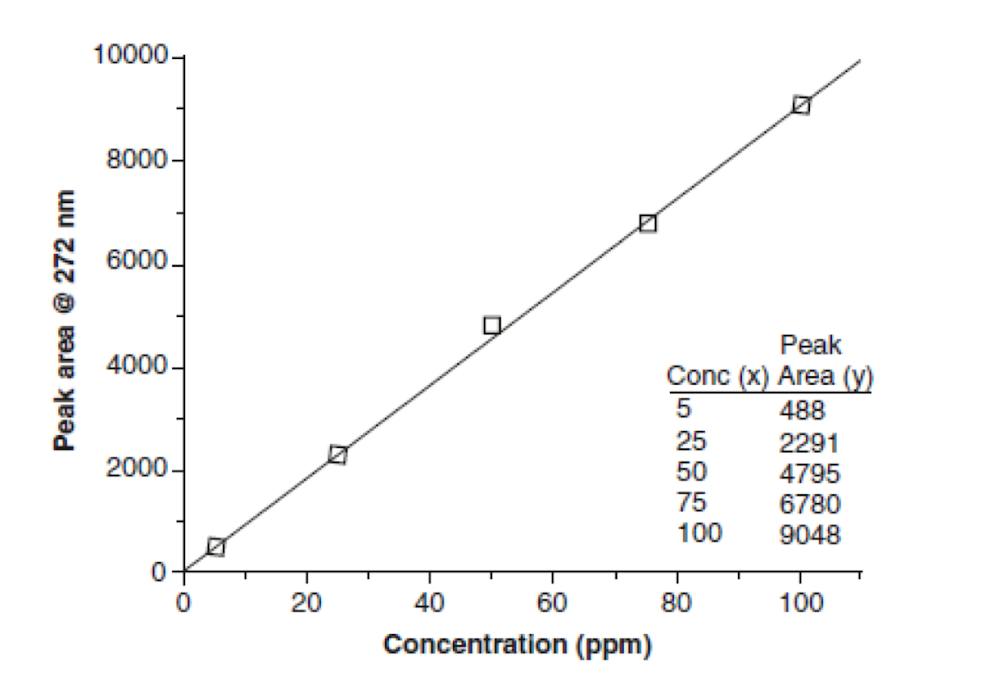
Figura 4.4 Una curva estándar típica de una parcela que muestra los puntos, datos, y la línea de mejor ajuste generado. Los datos utilizados para trazar la curva se presentan en el gráfico.
En el gráfico en la Figura 4.4 muestra todos los puntos de los datos y aparece una línea recta pasando a través de la mayoría de los puntos. La línea casi pasa a través del origen, esto es así porque la concentración cero no debe producir una señal a los 272 nm. Sin embargo, la línea no es perfectamente recta pasando por todos los puntos (y nunca lo es) y por eso no alcanza el punto de origen.
Para determinar la concentración de cafeína en una muestra que dio un área de, digamos, 4,000, podríamos interpolar a la línea y luego dibujar una línea hacia el eje x. Siguiendo una línea hasta el eje x (concentración), podemos estimar la solución que debe tener aproximadamente para 42–43 ppm de cafeína.
Podemos determinar matemáticamente el mejor ajuste de la línea mediante el uso de regresión lineal. Tenga en cuenta la ecuación de una línea recta, que es y= ax+b, donde a es la pendiente y b es la ordenada al origen y-interceptado. Para determinar la pendiente a y la intercepción en y, se utilizan las ecuaciones de regresión que se muestran a continuación. Determinemos a y b por lo tanto, para cualquier valor de y (medido), se puede determinar la concentración (x):
Ec. 4.20, Ec.4.21
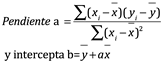
Donde:
![]()
Calculadoras de bajo costo y software de hoja de cálculo pueden calcular fácilmente las ecuaciones de regresión, por lo que no se hace ningún intento de ir a través de las matemáticas en estas fórmulas.
Las fórmulas dan lo que se conoce como la línea de regresión de y sobre x, asumiendo que el error se produce en la dirección de y. La línea de regresión representa la relación promedio entre todos los puntos de datos y por lo tanto, es una línea equilibrada. Estas ecuaciones también suponen que el ajuste de la recta no tiene que pasar por el origen, que en un principio no tiene mucho sentido. Sin embargo, a menudo hay interferencias de fondo, de modo que incluso a concentraciones de cero, se puede observar una señal débil. En la mayoría de las situaciones, en el cálculo del origen que pasa por cero se obtendrán los mismos resultados.
4.4.2 Coeficiente de correlación
Al observar cualquier tipo de correlación, incluyendo las lineales, las preguntas siempre surgen en torno a cómo dibujar la línea mientras intercepta todos los puntos englobados en los datos y qué tan bien los datos se ajustan a la línea recta. Lo primero que se debe hacer con cualquier grupo de datos es trazar para ver si los puntos se ajustan a una línea recta. Con solo mirar los datos representados, es bastante fácil de hacer un juicio sobre la linealidad de la recta. También podemos seleccionar regiones en la línea donde no existe una relación lineal. Las figuras siguientes ilustran las diferencias en las curvas de calibración; la Fig. 4.5a muestra una buena correlación de los datos y la Fig. 4.5b muestra una correlación pobre. En ambos casos, podemos trazar una línea recta a través de los puntos referentes a los datos. Ambas curvas exhiben la misma línea recta, pero la precisión es más ausente para la segunda.
Hay otras posibilidades cuando se trabaja con las curvas de calibración. Figura 4.6a muestra una buena correlación entre x y y, pero en la dirección negativa, y la Fig. 4.6b ilustra los datos que no tienen correlación en absoluto.
El coeficiente de correlación define qué tan bien los datos se ajustan a una línea recta. Para una curva estándar, la situación ideal sería que todos los puntos de datos se encuentran perfectamente en una línea recta. Sin embargo, esto no es el caso, ya que los errores se introducen en la toma de las normas y la medición de los valores físicos (observaciones).
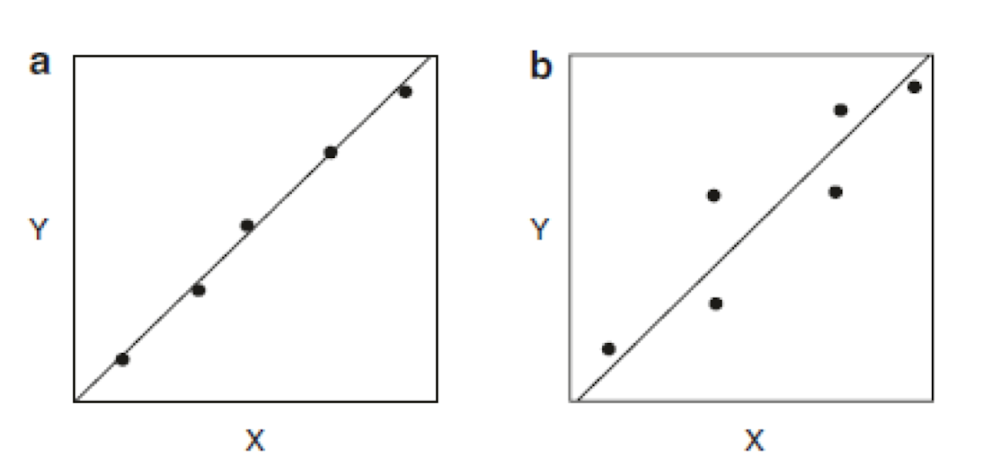
Figura 4.5 Los ejemplos de las curvas de calibración que muestra la relación entre las variables x y y cuando existe (a) una alta cantidad de correlación y (b) una menor cantidad de correlación. Ambas líneas tienen la misma ecuación.
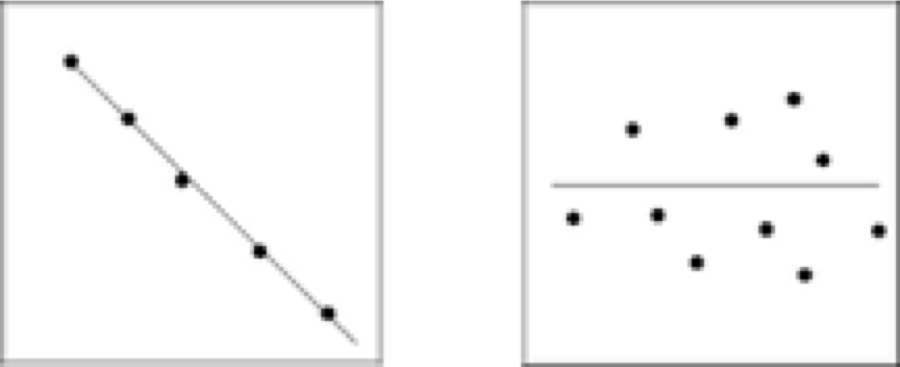
Figura 4.6 Los ejemplos de las curvas de calibración muestran la relación entre las variables x y y variables cuando existen (a) una alta cantidad de correlación negativa y (b) ninguna correlación entre los valores de x y y.
El coeficiente de correlación y el coeficiente de determinación se definen a continuación. Esencialmente, todas las hojas de cálculo y software de graficación calcularán automáticamente los valores:
Ec. 4.25
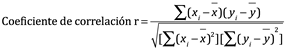
Para nuestro ejemplo de la curva estándar de la cafeína de la Figura. 4.3, r = 0.99943 (los valores usualmente se informan con por lo menos cuatro cifras significativas).
Para las curvas de calibración, pretendemos que el valor de r sea tan cercano como sea posible a +1.0000 o -1.000, ya que con este valor es una correlación perfecta (una línea recta perfecta). Generalmente, en el trabajo analítico, la r debe ser 0.9970 o mejor (esto no se aplica a los estudios biológicos).
El coeficiente de determinación (r2) se utiliza a menudo, ya que da una mejor percepción de la línea recta a pesar de que no indica la dirección de la correlación. El r2 para el ejemplo presentado anteriormente es 0,99886, lo que representa la proporción de la varianza de absorbancia (y) que se puede atribuir a su regresión lineal de la concentración (x). Esto significa que aproximadamente 0.114% de la variación de la línea recta (1.0000-0.99886 = 0.00114 × 100% = 0.114%) no varía con los cambios en xy y, y por lo tanto, es debido a una variación indeterminada. Se espera normalmente una pequeña cantidad de variación.
4.4.3 Los errores en las líneas de regresión
Mientras que el coeficiente de correlación nos dice algo sobre el error o variación de ajustes de la curva lineal, no siempre muestran la imagen completa. Además, ni el coeficiente de regresión ni la correlación lineal indicarán que un conjunto particular de datos tiene una relación lineal. Solo proporcionan una estimación de la forma de asumir la línea, es lineal a una a priori. Como se ha indicado antes, el trazado de los datos es crítico cuando se mira en cómo encajan los datos sobre la curva (en realidad, una línea). Un parámetro que se utiliza a menudo es la y-residuos, que son simplemente las diferencias entre los valores observados y los valores calculados (de la línea de regresión). Equipo de software de gráficos avanzados en realidad puede graficar los residuales para cada punto de datos como una función de la concentración. Sin embargo, el trazado de los residuos por lo general no es necesario porque los datos que no encajan en la línea, son por lo general bastante obvios. Si los residuos son grandes para toda la curva, entonces todo el método necesita ser evaluado cuidadosamente. Sin embargo, la presencia de un punto que obviamente está fuera de la línea, mientras que el resto de los puntos encajan muy bien, probablemente indica un estándar incorrectamente hecho.
Una forma de reducir la cantidad de error es incluir más repeticiones de los datos, tales como la repetición de las observaciones con un nuevo conjunto de normas. La réplica x y y valores se pueden introducir en la calculadora u hoja de cálculo como puntos separados para las determinaciones de regresión y coeficientes. Otra opción, probablemente más deseable, es ampliar las concentraciones a las cuales se toman las lecturas. Recopilación de observaciones en más puntos de datos (concentraciones) producirá una curva de mejor nivel. Sin embargo, el aumento de los datos más allá de siete u ocho puntos por lo general no es beneficioso.
Trazado de intervalos de confianza, o bandas o límites, en la curva estándar junto con la línea de regresión es otra manera de obtener una perspectiva de la fiabilidad de la curva estándar. Bandas de confianza definen la incertidumbre estadística de la línea de regresión en una probabilidad seleccionada (95%) utilizando la t-estadística y la desviación estándar calculada de esa forma. En algunos aspectos, las bandas de confianza de la curva estándar son similares al intervalo de confianza discutido en el punto 4.3.1. Sin embargo, en este caso estamos ante una línea en lugar de un intervalo de confianza alrededor de una media. Figura 4.7 muestra los datos de la cafeína de la curva estándar presentan antes, excepto algunos de los números se han modificado para mejorar las bandas de confianza. Las bandas de confianza (líneas discontinuas) consisten tanto un límite superior y un límite inferior que definen la variación del valor del y-eje. Las bandas superior e inferior son más estrechas en el centro de la curva y son más anchas que la curva se desplaza a las concentraciones normales superiores o inferiores.
En cuanto a la Fig. 4.7 de nuevo, tenga en cuenta que las bandas de confianza muestran qué cantidad de variación esperamos en un área de pico a una concentración particular. A 60 ppm de concentración, yendo desde el x-eje de las bandas y la interpolación de la y-eje, vemos que con nuestros datos, el intervalo de confianza del 95% del área del pico observado será 4.000-6.000. En este caso, la variación es grande y no sería aceptable como una curva estándar y se presenta aquí solo para fines ilustrativos.
Barras de error también se puede utilizar para mostrar la variación de y en cada punto de datos. Varios tipos de estadísticas de error o variación pueden ser usados ??como error estándar, desviación estándar, o el porcentaje de datos (es decir, 5%). Cualquiera de estos métodos proporcionan una indicación visual de la variación experimental.
Incluso con buenos datos de la curva estándar, pueden surgir problemas si la curva estándar no se utiliza correctamente. Un error común es extrapolar más allá de los puntos de datos utilizados para construir la curva. Figura 4.8 ilustra algunos de los posibles problemas que pueden surgir cuando se utiliza la extrapolación. Como se muestra en la Fig. 4.8, la curva o la línea no puede ser lineal fuera de la zona en la que se recogieron los datos. Esto puede ocurrir en la región cerca del origen o especialmente al nivel de concentración más alta.
Por lo general, una curva estándar pasará por el origen, pero en algunas situaciones puede en realidad que esta inicie de una concentración cero como se aborda en algunos ensayos. En el otro extremo de la curva, a concentraciones más altas, es bastante común para una meseta que se alcance en el que el parámetro medido no cambia mucho con un aumento en la concentración. Se debe tener cuidado en el límite superior de la curva para asegurar que los datos de incógnitas no se recogen fuera de las normas de la curva. Punto Z en la Fig. 4.7 debe evaluarse cuidadosamente para determinar si el punto es un valor atípico o si la curva está realmente disminuyendo. Recopilar varios conjuntos de datos a concentraciones aún más altas debería aclarar esto. Independientemente, las incógnitas deben medirse solo en la región de la curva que está lineal.
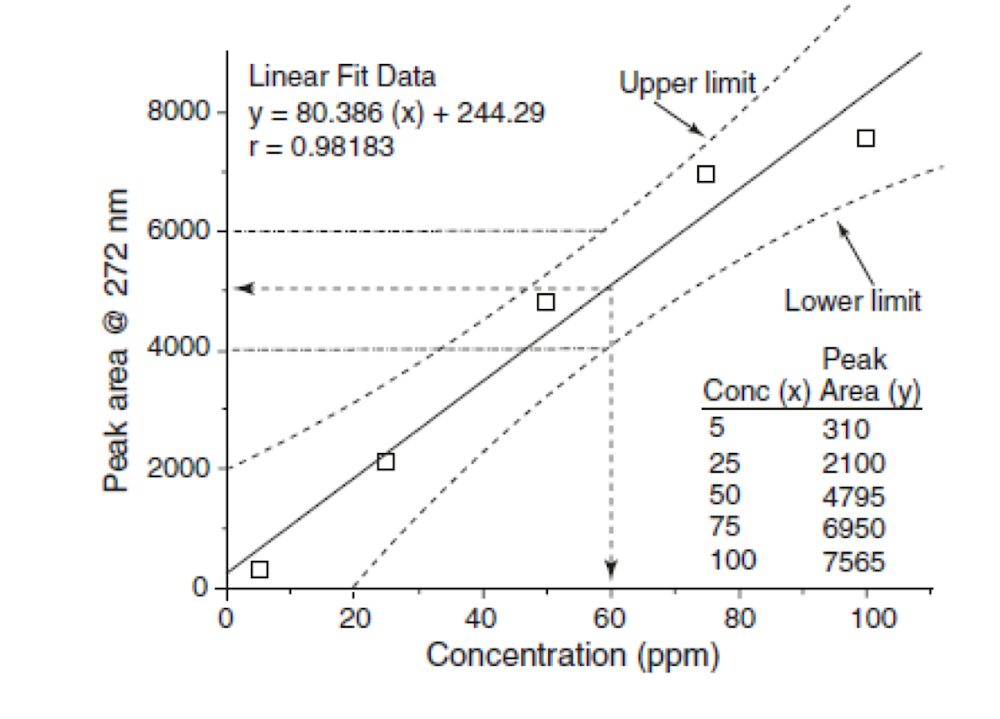
Figura 4.7 Un gráfico de la curva estándar que muestra las bandas de confianza. Los datos utilizados para trazar la gráfica se representan en el gráfico como son la ecuación de la recta y el coeficiente de correlación.
 21.00.40.png)
Figura 4.8 Una parcela curva estándar que muestra las posibles desviaciones en la curva en los límites superior e inferior.
4.5 Informe de resultados
Al tratar con los resultados experimentales, siempre nos enfrentamos a los informes de datos en un modo en que indican la sensibilidad y la precisión del ensayo. Lo ideal es no pretender exagerar o subestimar la sensibilidad del ensayo, y por lo tanto nos esforzamos para informar de un valor significativo, ya sea una media, desviación estándar, o algún otro número. Las tres secciones siguientes discuten cómo podemos evaluar los valores experimentales con el fin de ser precisos al informar sobre los resultados.
4.5.1 Personajes importantes (cifras significativas)
El término cifra significativa se utiliza en lugar de describir libremente con algún juicio el número de dígitos notificables en un resultado. A menudo, el juicio no es una base sólida, y los dígitos significativos se pierden o dígitos sin sentido se conservan. Las reglas exactas se proporcionan a continuación para ayudar a determinar el número de cifras significativas a reportar. Sin embargo, es importante mantener una cierta flexibilidad cuando se trabaja con cifras significativas.
El uso adecuado de cifras significativas está destinado a dar una indicación de la sensibilidad y la fiabilidad de un método analítico. Entonces, los valores que se declaran deben contener únicamente cifras significativas. Un valor se compone de cifras significativas cuando contiene todos los dígitos conocidos para ser verdadero y un último dígito que está en duda. Por ejemplo, un valor informado 64.72 contiene cuatro cifras significativas, de los cuales tres dígitos son ciertos (64.7) y el último dígito es incierto. Así, el 2 es algo incierto y podría ser o bien 1 o 3. Como regla, los números que se presentan en un valor representan las cifras significativas, independientemente de la posición de los puntos decimales. Esto también es cierto para los valores que contienen ceros, siempre que estén delimitados en cada lado por un número. Por ejemplo, 64.72, 6.472, 0.6472 y 6.407 todos contienen cuatro cifras significativas. Note que el cero a la derecha del punto decimal solo es usado para indicar que no existen números por encima de 1. Nosotros podríamos reportar el valor como .6472, pero el uso del 0 resulta más adecuado, aunque sabemos que no hay otro número de valor inadvertido implicado en ese valor.
Consideraciones especiales son necesarias para que los ceros que pueden o no pueden ser significativos:
1. Los ceros después de la coma decimal son siempre cifras significativas. Por ejemplo, 64.720 y 64.700, ambos contienen cinco cifras significativas.
2. Los ceros antes de un punto decimal sin otros dígitos anteriores no son significativos. Como se ha indicado antes, 0.6472 solo contiene cuatro cifras significativas.
3. Los ceros después de la coma decimal no son significativos si no hay dígitos antes del punto decimal. Por ejemplo, 0.0072 no tiene dígitos antes del punto decimal; por lo tanto, este valor contiene dos cifras significativas. Por el contrario, el valor 1.0072 contiene cinco cifras significativas.
4. Los ceros finales en un número no son significativos a menos que se indique lo contrario. Así, el valor 7,000 contiene solo una cifra significativa. Sin embargo, la adición de un punto decimal y otro cero da el número 7,000.0, que tiene cinco cifras significativas.
Una buena manera de medir la importancia de ceros, si las reglas anteriores se vuelven confusas, es convertir el número a la forma exponencial. Si los ceros se pueden omitir, entonces ellos no son significativos. Por ejemplo, 7000 expresado en forma exponencial es 7x103 y contiene una cifra significativa. Con 7000.0, los ceros se conservan y se convierte en el número 7.0000×103. Si nos vamos a convertir a 0,007 en forma exponencial, el valor es de 7×10-3 y solo una cifra significativa se indica. Como regla, la determinación de cifras significativas en operaciones aritméticas es dictado por el valor que tiene el menor número de cifras significativas. La forma más fácil para evitar cualquier confusión es llevar a cabo todos los cálculos y luego redondear la respuesta final a los dígitos apropiados. Por ejemplo, 36.54 × 238 × 1.1 = 9.566,172, y debido a que 1.1 contiene solo dos cifras significativas, la respuesta sería reportada como 9600 (recuerde, los dos ceros no son significativos). Este método funciona bien para la mayoría de los cálculos, excepto cuando se añada o los números que contienen decimales están siendo restados. En esos casos, el número de cifras significativas en el valor final está determinado por los números que siguen al punto decimal. Así, cuando la adición de 7.45 + 8.725 = 16.175, la suma se redondea a 16.18 porque 7.45 tiene solo dos números después del punto decimal. Del mismo modo, 433.8-32,66 da 401.14, que redondea a 401.1.
Una palabra de precaución se justifica cuando se utiliza la regla simple que se ha señalado anteriormente, ya que hay una tendencia a subestimar las cifras significativas en la respuesta final. Por ejemplo, tomar la situación en la que se determinó la cafeína en una solución desconocida ser 43.5 ppm. Tuvimos que diluir la muestra 50 veces usando un matraz aforado con el fin de ajustarnos a lo desconocido dentro de la gama de nuestro método. Para el cálculo de la cafeína en la muestra original, multiplicamos nuestro resultado por 50 o 43.5 x 50 = 2,175 μg/ml en la solución desconocida. Sobre la base de nuestra regla anterior, entonces podríamos redondear el número a una cifra significativa (porque 50 contiene una cifra significativa) y comunicar el valor como 2,000. Sin embargo, hacer esto en realidad subestima la sensibilidad de nuestro procedimiento, porque ignoramos la precisión del matraz volumétrico utilizado para la dilución. A- matraz volumétrico clase A tiene una tolerancia de 0,05 ml; por lo tanto, de una manera más razonable para expresar el factor de dilución sería 50.0 en lugar de 50. Ahora se han incrementado las cifras significativas de la respuesta en dos, y el valor se convierte en 2,180 μg/ml.
Como se puede ver, la consideración de cifras significativas y su modo de adopción requiere una inspección minuciosa. Las directrices pueden ser útiles, pero no siempre funcionan a menos que cada valor individual o número se examinen de cerca.
4.5.2 Pruebas y datos atípicos
Inevitablemente, durante el curso de trabajar con datos experimentales, nos encontraremos con los valores atípicos que no coinciden con los otros. ¿Se puede rechazar ese valor y por lo tanto no utilizarlo en el cálculo final de los resultados reportados?
La respuesta es “muy raramente” y solo después de una cuidadosa consideración. Si está rechazando sistemáticamente datos para ayudar al ensayo a verse mejor, entonces usted está tergiversando los resultados y la precisión del ensayo. Si el valor erróneo es resultado de un error de identificación en esa prueba en particular, entonces es probable que sea seguro dejar el valor. Una vez más, se recomienda precaución porque se puede rechazar un valor que está más cerca del verdadero valor que algunos de los otros valores.
De modo consistente la ausencia de exactitud o precisión indica que se utilizó una técnica inadecuada o reactivo incorrecto o que el diseño o ejecución de la prueba no era muy bueno. Lo mejor es hacer cambios en el procedimiento o cambiar métodos en lugar de tratar de encontrar formas de eliminar los valores no deseados.
Hay varias pruebas para rechazar los datos atípicos. Además, el uso de estimadores estadísticos más robustos de la media de la población puede minimizar los efectos de los valores extremos atípicos. La prueba más simple para rechazar los datos de valor atípico es la prueba Q de Dixon a menudo llamada simplemente la prueba Q[9]. La ventaja es que esta prueba se puede calcular fácilmente con una simple calculadora y es útil para un pequeño grupo de datos. En esta prueba, un Q-valor se calcula como se muestra a continuación y en comparación con los valores de una tabla. Si el valor calculado es mayor al valor de la tabla, a continuación, la medición es cuestionable, y puede ser rechazada con un nivel de confianza del 90% en una prueba particular:
Ec. 4.26
![]()
Donde:

Tabla 4.4 Valores Q referentes al rechazo de resultados
 21.08.52.png)
La tabla 4.4 proporciona el rechazo de Q-valores para un nivel de confianza del 90%. El siguiente ejemplo muestra cómo se utiliza la prueba para el nivel de humedad de pan sin cocer para el que cuatro repeticiones se realizaron valores que dan de 64.53, 64.45, 64.78 y 55.31. El valor de 55.31 parece que es demasiado bajo en comparación con los otros resultados. ¿Se puede rechazar ese valor? Para nuestro ejemplo, x1 es el valor cuestionable (55.31) y x2 es el vecino más cercano a x1 (que es 64.45). La propagación (W) es el alto valor menos la medición más baja, que es 64.78-55.31:
Ec. 4.27
![]()
De la Tabla 4.4, Vemos que el valor Q calculado debe ser mayor que 0,76 para rechazar los datos. Por lo tanto, tomamos la decisión de rechazar el valor de humedad 55,31% y no incluirlo en el cálculo de la media.
4.6 Resumen
Este texto se centra en los métodos estadísticos para medir la variabilidad de los datos, precisión, etc., y el procesamiento matemático básico que se puede utilizar en la evaluación de un grupo de datos. Por ejemplo, debería ser casi una segunda naturaleza para determinar una media, la desviación estándar, y CV en la evaluación de los análisis replicados de una muestra individual. En la evaluación de las curvas de calibración lineales, mejores ajustes de línea siempre se deben determinar junto con los indicadores del grado de linealidad (coeficiente de correlación o coeficiente de determinación). Afortunadamente, la mayor parte de hojas de cálculo y software de gráficos llevará a cabo fácilmente los cálculos por usted. Directrices están disponibles para permitir reportar los resultados analíticos de una manera que dice algo acerca de la sensibilidad y confianza de una prueba en particular. En una sección está incluido, que describe la sensibilidad y límite de detección en relación con los diversos métodos analíticos y políticas de la agencia de regulación, información adicional incluye el uso correcto de cifras significativas, las reglas para el redondeo de números, y el uso de varias pruebas para rechazar valores individuales groseramente aberrantes (discrepantes).
4.7 Autoevaluación
1. Un método para cuantificar un componente de alimento en particular se informó ser más específico y preciso que el método B, pero el Método A mostró una menor precisión. Explique lo que esto significa.
2. Usted está considerando la adopción de un nuevo método de análisis en el laboratorio para medir el contenido de humedad de los productos de cereales. ¿Cómo determinaría la precisión del nuevo método para compararlo con el método antiguo? Incluyen cualquier ecuación que se utilizará para los cálculos necesarios.
3. Una muestra que se sabe que contiene 20 g/L de glucosa se analiza mediante dos métodos. Diez determinaciones se realizaron para cada método y se obtuvieron los siguientes resultados:
 21.15.11.png)
A) Precisión y exactitud
(i) ¿Qué método es más preciso? ¿Por qué se dice esto?
(ii) ¿Qué método es más exacto? ¿Por qué se dice esto?
B) En la ecuación para determinar la desviación estándar, n-1 se utilizó en lugar de n. ¿La desviación estándar habría sido más pequeña o más grande para cada uno de esos valores si simplemente se hubiera usado n?
C) Usted ha determinado que los valores obtenidos con el Método B, ¿no deben aceptarse si están fuera del rango de dos desviaciones estándar de la media? ¿Qué rango de valores será aceptable?
D) ¿Los datos anteriores le dicen algo asobre la especificidad del método? Describir lo que la “especificidad” del método significa cuando justifique su respuesta.
4. Diferenciar “desviación estándar” de “coeficiente de variación”, “error estándar de la media,” e “intervalo de confianza”.
5. Diferenciar los términos “error absoluto” frente a “error relativo” ¿Qué es más útil? ¿Por qué?
6. Para cada uno de los errores descritos a continuación en la realización de un procedimiento analítico, clasificarlos el error como error aleatorio, error sistemático, o serie de errores, y describa una manera de superar dicho error:
(a) Pipeta automática entregando de modo consistente 0,96 ml en vez de 1,00 ml.
(b) Substrato no se agregó a un tubo en un ensayo de enzimas.
7. Diferenciar los términos “sensibilidad” y “límite de detección”.
8. El coeficiente de correlación para la curva estándar A se informa como 0,9970. El coeficiente de determinación para el estándar de la curva B se reporta como 0,9950. ¿En cuál caso los datos se ajustan mejor a una línea recta?
4.8 Problemas de práctica
1. ¿Cuántas cifras significativas se encuentran en los siguientes números: 0.0025, 4.50, 5.607?
2. ¿Cuál es la respuesta correcta para el siguiente cálculo expresado en la cantidad adecuada de cifras significativas? (2.43x0.01672)/1.83215=
3. Dados los siguientes datos sobre materia seca (88.62, 88.74, 89.20, 82.20), determine la media, la desviación estándar y el CV. ¿Es aceptable la precisión de este conjunto de datos? ¿Puede rechazar el valor 82.20 ya que parece ser diferente de los demás? ¿Cuál es el nivel de confianza del 95% en el que esperaría que sus valores cayeran si se repitiera la prueba? Si el valor verdadero para la materia seca es 89.40, ¿cuál es el porcentaje de error relativo?
4. Comparación de los dos grupos de datos de la curva estándar por debajo para la determinación de sodio mediante espectroscopia de emisión atómica. Dibujar las curvas estándar utilizando papel cuadriculado o un programa de computadora. ¿Qué grupo de datos proporciona una curva de mejor calidad? Tenga en cuenta que la absorbancia de la radiación emitida a 589 nm aumenta proporcionalmente a la concentración de sodio. Calcular la cantidad de sodio en una muestra con un valor de 0,555 para la emisión a 589 nm. Use ambos grupos de curvas estándar y comparar los resultados.
 21.23.23.png)
Respuestas
1) 2,3,4
2) 0.00222
3) Media=87.19, SDn-1=3.34:
![]()
Entonces, la precisión es aceptable porque representa menos del 5%:
![]()
Q calc=0.92, sin embargo el valor de 82.20 puede ser rechazado porque representa más de 0.76 refiriendo a la Tabla 4.4 considerando 4 como el número de observaciones:
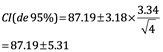
Error relativo=%Erel donde la media es 87.19 y el valor verdadero es 89.40:
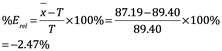
4) Usando regresión lineal obtenemos
Grupo A: y = 0.0504x − 0.0029, r2 = 0.9990.
Grupo B: y = 0.0473x + 0.0115, r2 = 0.9708.
Group A: r2 está más cerca de 1.000 y es más lineal y, por lo tanto, la mejor curva estándar.
El sodio en las muestras del grupo A en la construcción de una curva estándar es
0.555 = 0.0504x - 0.0029, x = 11.1 µg /mL
El sodio en las muestras del grupo A en la construcción de una curva estándar es
0.555 = 0.0473x + 0.0115, x = 11.5 µg /mL
Referencias
[1] Ikonen, K. & Wehde, Katherine & Khalida, Habeb & Kenttämaa, Hilkka. (2019). Bias, Limit of Detection, and Limit of Quantitation for the ASTM D2425 Method Updated in 2019. Journal of Chromatography A. 1614. 460705. 10.1016/j.chroma.2019.460705.
[2] Tschmelak, Jens & Proll, Guenther & Gauglitz, Günter. (2004). Immunosensor for estrone with equal limit of detection as common analytical methods. Analytical and bioanalytical chemistry. 378. 744-5. 10.1007/s00216-003-2357-4.
[3] Berger, Elliott & Johansson, M. & Madison, D. & Myers, M.. (2020). Comments Regarding Environmental Protection Agency 40 CFR Part 211 Product Noise Labeling Hearing Protection Devices.
[4] Crosby, Daoid. (2012). Practical Statistics for Engineers and Scientists. Technometrics. 30. 234-235. 10.1080/00401706.1988.10488377.
[5] Pergantis, Spiros. (2006). Young Analytical Scientists issue. Journal of Analytical Atomic Spectrometry. 21. 1125-1126. 10.1039/b614314h.
[6] Ellison, SLR, Barwick, VJ, Farrant, TJD (2009) Practical Statistics for the Analytical Scientist: A Bench Guide, Chapter 5, 2nd ed. RSC Publishing, Cambridge, UK.
[7] Xiong, Jiaqing & Jiao, Chenlu & Li, Chenmei & Zhang, Desuo & Chen, Yuyue. (2014). The standard curves of CR aqueous solution.
[8] Shao, Jianbin & Zhang, Yiping. (2019). Determination of caffeine content in tea beverages. IOP Conference Series: Earth and Environmental Science. 330. 042056. 10.1088/1755-1315/330/4/042056.
[9] Napitupulu, Darmawan. (2020). Cochran Q-Test for Criteria Validation of PeGI Framework. Journal of Physics: Conference Series. 1430. 012037. 10.1088/1742-6596/1430/1/012037.
Autores:
Eduardo Ochoa Hernández
Nicolás Zamudio Hernández
Lizbeth Guadalupe Villalon Magallan
Mónica Rico Reyes
Pedro Gallegos Facio
Gerardo Sánchez Fernández
Rogelio Ochoa Barragán